Автор: Денис Аветисян
Новый подход сочетает поиск по дереву Монте-Карло с механизмом накопления опыта, позволяя языковым моделям совершенствовать свои навыки рассуждений без переобучения.
Купил акции по совету друга? А друг уже продал. Здесь мы учимся думать своей головой и читать отчётность, а не слушать советы.
Бесплатный телеграм-канал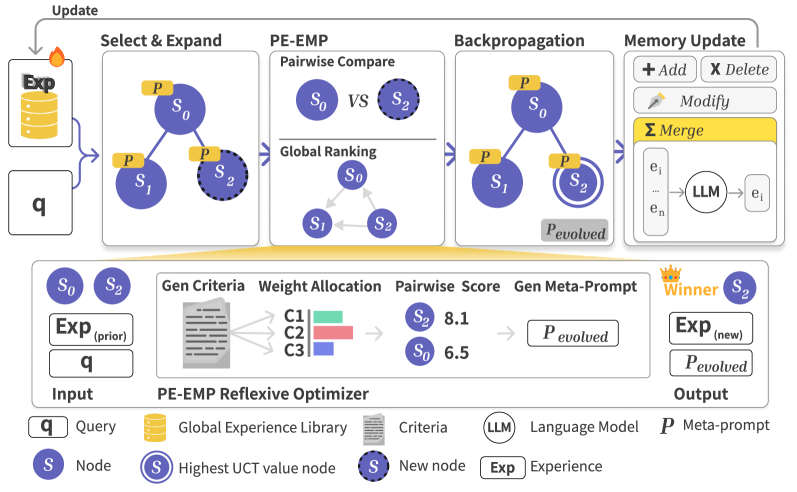
Представлен Empirical-MCTS — фреймворк, использующий двойной опыт и мета-подсказки для непрерывной эволюции агента на основе Монте-Карло поиска.
Несмотря на значительные успехи больших языковых моделей (LLM) в решении сложных задач, существующие подходы к построению логических цепочек часто остаются без учета накопленного опыта. В данной работе, ‘Empirical-MCTS: Continuous Agent Evolution via Dual-Experience Monte Carlo Tree Search’, предлагается новый фреймворк, объединяющий поиск по дереву Монте-Карло (MCTS) с механизмом непрерывного обучения на основе опыта и эволюцией мета-подсказок. Предложенный Empirical-MCTS позволяет LLM не только эффективно исследовать пространство решений, но и динамически совершенствовать свои стратегии рассуждений без обновления параметров модели. Способны ли подобные системы эмпирического обучения приблизить нас к созданию действительно разумных агентов, способных к адаптивному и долгосрочному решению проблем?
Пределы масштабирования: За гранью возможностей трансформеров
Несмотря на впечатляющие возможности больших языковых моделей (LLM), они зачастую испытывают трудности при решении сложных, многоступенчатых задач, требующих последовательного логического вывода. В то время как LLM превосходно справляются с распознаванием паттернов и генерацией текста, анализ ситуаций, где необходимо объединить несколько фактов и выполнить ряд промежуточных шагов для достижения конечного результата, представляет для них серьезную проблему. Например, задачи, требующие понимания причинно-следственных связей, планирования действий или решения логических головоломок, часто вызывают ошибки даже у самых передовых моделей. Это связано с тем, что LLM, по сути, являются статистическими моделями, которые предсказывают следующее слово в последовательности, а не действительно «понимают» смысл происходящего, что ограничивает их способность к абстрактному мышлению и глубокому рассуждению.
Несмотря на впечатляющие возможности больших языковых моделей, простое увеличение их размера демонстрирует снижение эффективности при решении сложных задач, требующих многоступенчатого рассуждения. Исследования показывают, что дальнейшее масштабирование моделей сталкивается с законом убывающей доходности, что указывает на необходимость принципиально новых подходов к обработке знаний и логическим выводам. Традиционные методы, основанные на последовательной обработке информации, зачастую не способны уловить тонкие взаимосвязи и зависимости, критически важные для надежного и точного рассуждения. Это стимулирует поиск альтернативных архитектур и алгоритмов, способных эффективно представлять знания и осуществлять сложные логические операции, выходящие за рамки простого увеличения количества параметров.
Традиционные методы обработки информации, основанные на последовательном анализе данных, зачастую оказываются неспособны уловить сложные взаимосвязи, необходимые для надежного рассуждения. В отличие от человеческого мышления, которое оперирует множеством ассоциаций и параллельных оценок, последовательная обработка информации вынуждает модель строить умозаключения шаг за шагом, что приводит к потере контекста и упущению важных деталей. Это особенно заметно при решении задач, требующих интеграции информации из различных источников или учета множества условий. В результате, даже самые мощные языковые модели демонстрируют ограниченные возможности в ситуациях, где требуется не просто запомнить факты, а активно использовать их для построения логических выводов и адаптации к новым обстоятельствам. Поэтому, для достижения действительно robust reasoning, необходим переход к методам, способным моделировать более сложные и динамичные процессы обработки информации.
Empirical-MCTS: Структурированный каркас для рассуждений
Представляется Empirical-MCTS — новая структура, объединяющая структурированный поиск и непрерывное обучение, использующая преимущества алгоритма Монте-Карло-Дерево Поиска (MCTS). Данный подход строит дерево поиска, что позволяет исследовать различные пути рассуждений и оценивать потенциальные исходы. В отличие от традиционного MCTS, Empirical-MCTS ориентирован на интеграцию с процессами обучения, позволяя накапливать и использовать опыт, полученный в ходе поиска, для улучшения последующих итераций и повышения эффективности решения задач. Основная цель — преодоление ограничений стандартного MCTS в сложных, динамических средах, требующих адаптации и обобщения знаний.
В основе подхода Empirical-MCTS лежит построение дерева поиска, которое позволяет исследовать множество возможных цепочек рассуждений и оценивать потенциальные исходы каждого пути. Каждый узел в дереве представляет собой промежуточное состояние рассуждений, а ветви — различные варианты продолжения. Алгоритм итеративно расширяет дерево, выбирая наиболее перспективные ветви на основе результатов моделирования и оценки. Это позволяет систематически исследовать пространство возможных решений и находить оптимальные стратегии, учитывая неопределенность и сложность задачи. Оценка потенциальных исходов производится с использованием механизмов моделирования, встроенных в алгоритм, что позволяет прогнозировать результаты различных действий и выбирать наиболее выгодные.
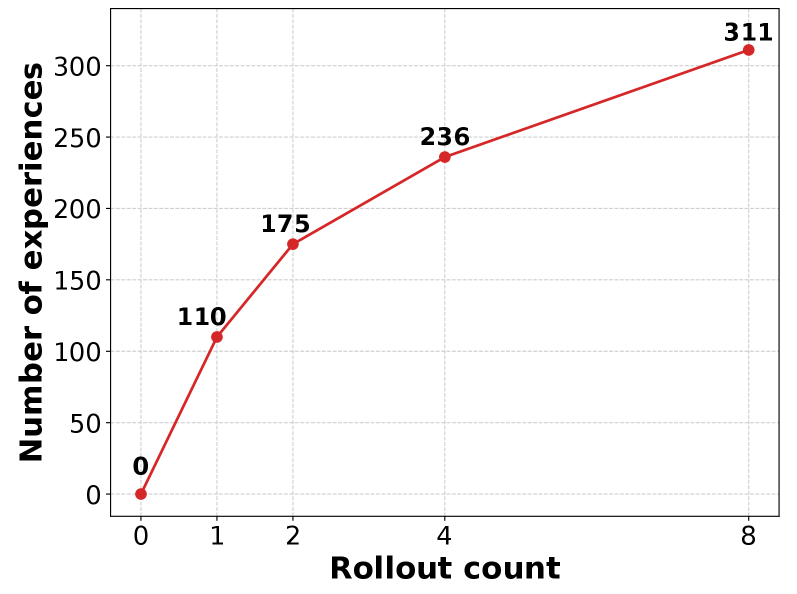
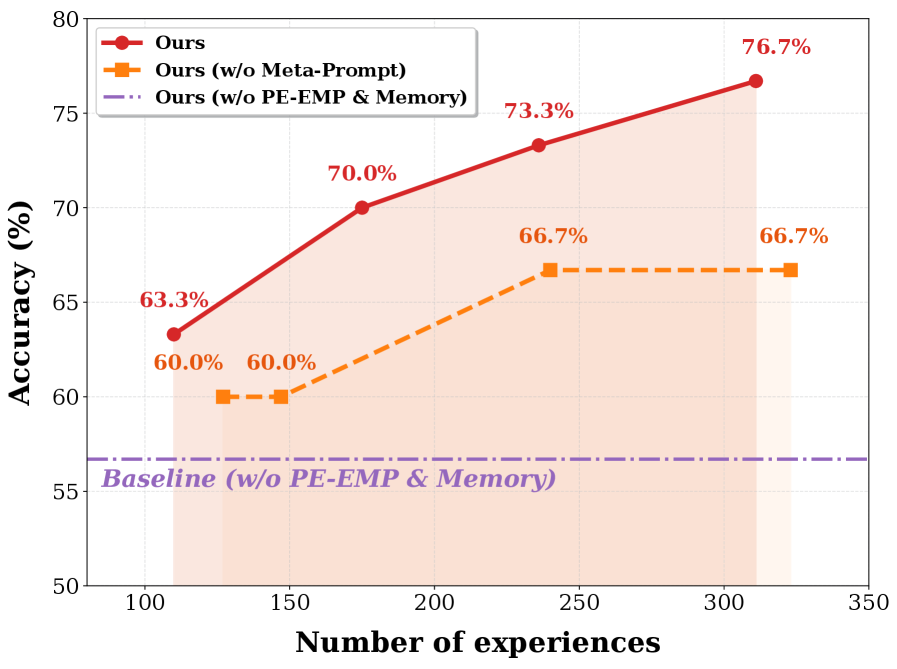
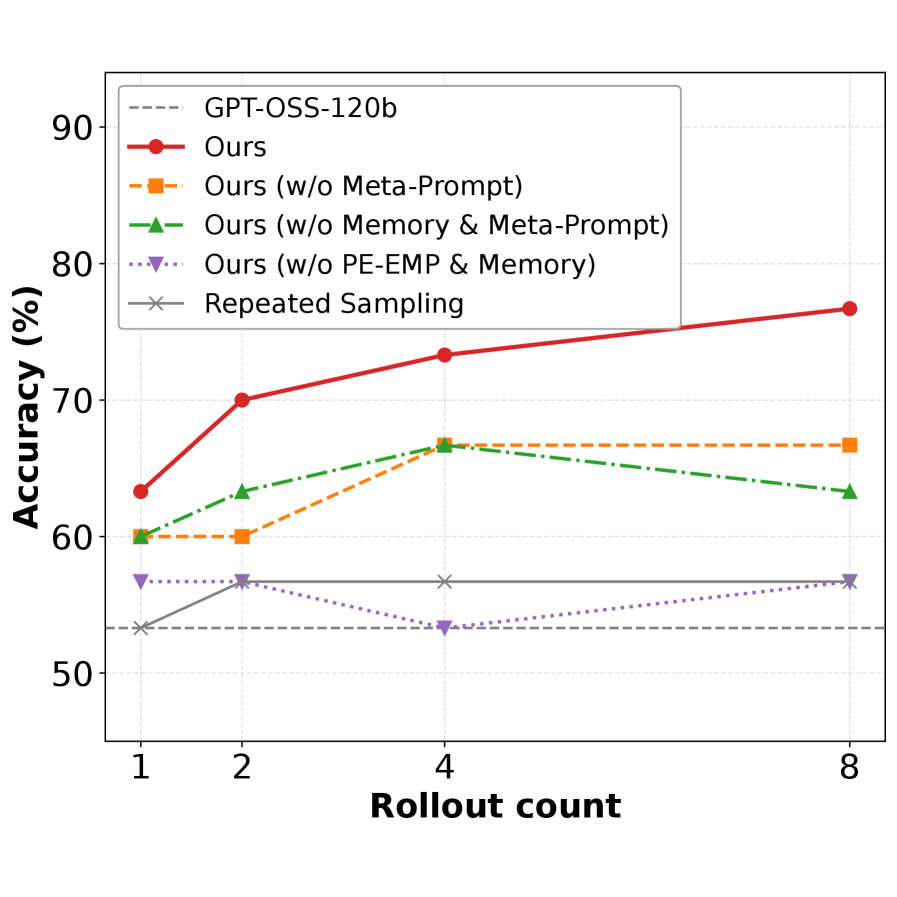
В основе Empirical-MCTS лежит агент оптимизации памяти (Memory Optimization Agent), который динамически обновляет глобальную библиотеку опыта (Experience Library) в процессе поиска. Эта библиотека содержит обобщенные знания, полученные в результате анализа различных путей рассуждений. Обновление библиотеки происходит в реальном времени, позволяя системе накапливать и использовать ранее полученные знания для повышения эффективности последующих поисков. На тестовом наборе данных AIME25 данный подход демонстрирует точность 73.3%, что свидетельствует о его способности эффективно использовать накопленный опыт для решения сложных задач.
Эволюция стратегий рассуждений с помощью парного сравнения
Ключевым компонентом Empirical-MCTS является Pairwise-Experience-Evolutionary Meta-Prompting (PEEMP), представляющий собой метод совершенствования Meta-Prompt посредством парного сравнения результатов генерации. PEEMP использует обратную связь, полученную при сопоставлении различных путей рассуждений, для итеративной оптимизации Meta-Prompt — основного шаблона, определяющего стратегию генерации ответов. В процессе анализа, система сравнивает два сгенерированных решения, определяя предпочтительный на основе заданных критериев. Эта информация используется для корректировки Meta-Prompt, что, в свою очередь, влияет на последующую генерацию и улучшает общую политику рассуждений.
Процесс уточнения стратегии рассуждений опирается на два метода оценки и ранжирования различных путей решения задач: модифицированный метод Борда (Enhanced Borda Count) и модель Брэдли-Терри (Bradley-Terry Model). Метод Борда позволяет присваивать баллы каждому пути решения, основываясь на его относительной эффективности по сравнению с другими, а модель Брэдли-Терри, в свою очередь, оценивает вероятность предпочтения одного пути другому, учитывая результаты парных сравнений. Комбинированное использование этих методов обеспечивает более точную и надежную оценку качества каждого пути рассуждений, что, в конечном итоге, способствует оптимизации стратегии и повышению точности решения задач.
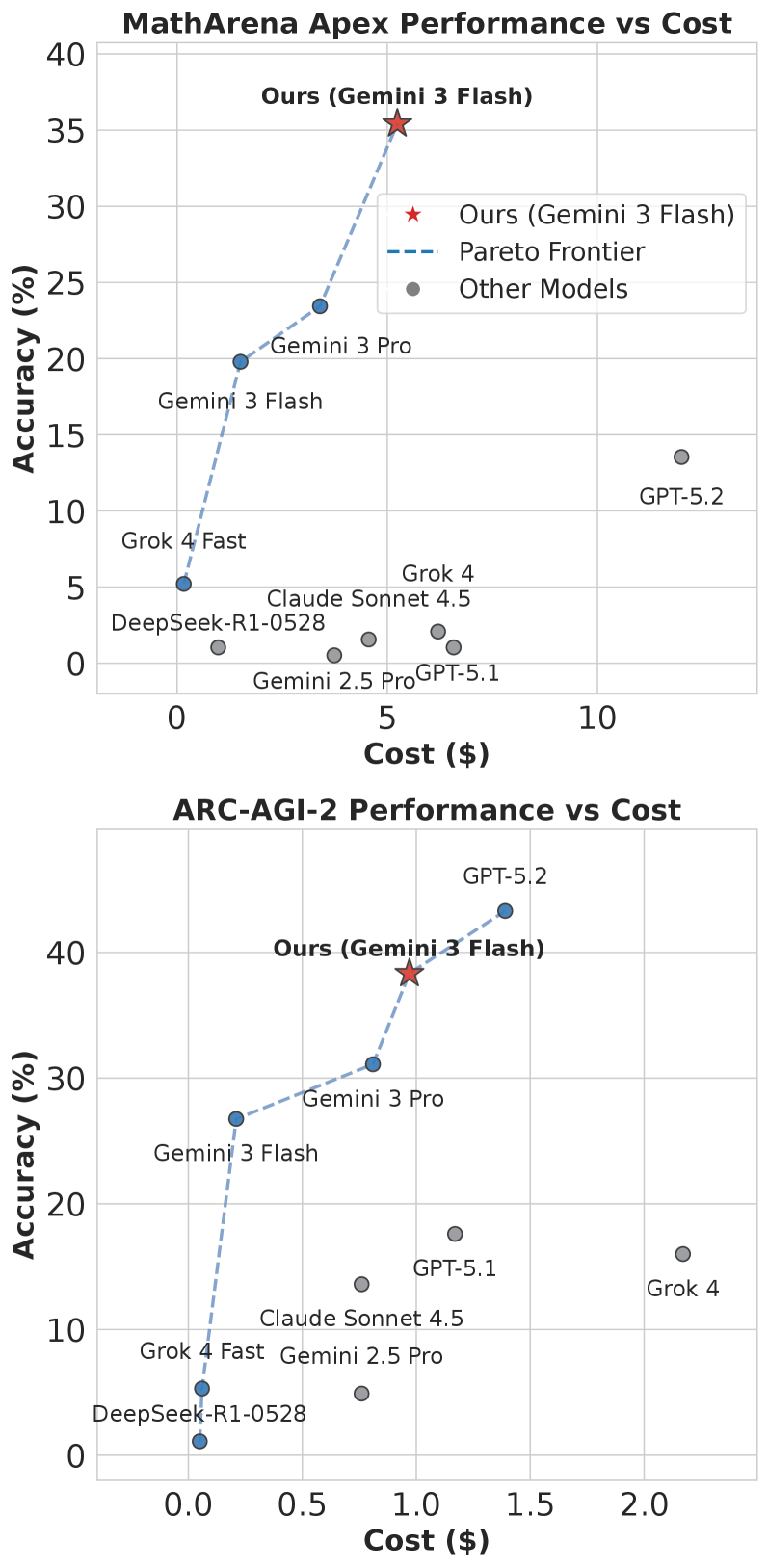
Интеграция механизма Forward Learning значительно повышает производительность модели в решении математических задач. На датасете MathArena Apex достигнута точность 4.17%, что существенно превосходит показатель базовой модели (0.00%) и LLaMA-Berry (2.08%). При этом использование Gemini 3 Flash позволяет снизить стоимость вычислений до $3.40, в то время как при использовании GPT-5.2 (High) стоимость составляет $12.00. Таким образом, Forward Learning не только улучшает качество решения задач, но и оптимизирует затраты на вычисления.
Оценка и валидация: Производительность в различных областях
Внедрение Empirical-MCTS в сочетании с передовыми большими языковыми моделями, такими как DeepSeek-V3.1-Terminus, gpt-oss-120b и Gemini 3 Pro, позволило достичь рекордных результатов на ключевых бенчмарках, включая AIME25, ARC-AGI-2 и MathArena Apex. Данный подход продемонстрировал превосходство в решении сложных задач, требующих не только обширных знаний, но и способности к структурированному логическому мышлению. Результаты подтверждают, что синергия между алгоритмами поиска на основе Монте-Карло и мощностью современных LLM открывает новые горизонты в области искусственного интеллекта, позволяя преодолевать ограничения, присущие исключительно масштабируемым моделям.
Результаты экспериментов демонстрируют существенное превосходство разработанного подхода в задачах, требующих сложного математического мышления и геометрических доказательств. В частности, на бенчмарке ARC-AGI-2 достигнута точность в 38.33%, что значительно превышает показатели Gemini 3 Pro (31.1%) и Grok 4 (16.0%). Аналогичные результаты получены и на MathArena Apex, где точность составила 35.42% при использовании Gemini 3 Flash. Данные показатели подтверждают эффективность предложенного метода в решении сложных проблем, требующих логического вывода и анализа, и указывают на потенциал структурированных подходов к рассуждениям в задачах, где простое масштабирование моделей оказывается недостаточным.
Полученные результаты ясно демонстрируют, что структурированные системы рассуждений обладают потенциалом преодолеть ограничения, присущие исключительно масштабированию моделей. В то время как увеличение размеров нейронных сетей часто приводит к улучшению производительности, сложные задачи, требующие логического вывода и математической точности, нуждаются в более организованном подходе. Вместо простого увеличения вычислительных ресурсов, Empirical-MCTS, интегрированный с мощными языковыми моделями, обеспечивает систематический процесс исследования и оценки возможных решений. Это позволяет достичь значительных успехов в областях, где традиционные методы, основанные на масштабировании, оказываются неэффективными, открывая новые горизонты для решения сложных проблем и развития искусственного интеллекта.
Перспективы развития: К общему искусственному интеллекту, способному к рассуждениям
В дальнейшем, исследования будут сосредоточены на расширении возможностей Empirical-MCTS за счет внедрения более сложных механизмов представления знаний и обучения. В частности, планируется разработка новых способов кодирования информации, позволяющих системе не просто оперировать фактами, но и устанавливать связи между ними, формируя более глубокое понимание задачи. Это включает в себя изучение возможностей использования нейронных сетей для представления знаний в компактной и эффективной форме, а также разработку алгоритмов обучения, позволяющих системе автоматически извлекать и обобщать знания из больших объемов данных. Успешная реализация этих направлений позволит значительно повысить способность Empirical-MCTS к решению сложных задач, требующих не только логического вывода, но и способности к адаптации и обучению на основе опыта.
Исследования направлены на объединение методов Training-Free GRPO и Self-Refine для существенного улучшения способности системы к самосовершенствованию стратегий рассуждений. Training-Free GRPO, не требующий предварительного обучения, позволит системе оперативно адаптироваться к новым задачам и условиям, в то время как Self-Refine обеспечит итеративное уточнение и оптимизацию процесса рассуждений на основе анализа собственных ошибок и результатов. Такая интеграция предполагает создание более гибкой и эффективной системы, способной самостоятельно выявлять и устранять недостатки в своих рассуждениях, что, в свою очередь, позволит ей решать более сложные и многогранные задачи, приближая её к уровню человеческого интеллекта.
Данное исследование направлено на создание более универсальных и адаптируемых систем искусственного интеллекта, способных решать широкий спектр сложных задач. Разрабатываемый подход призван выйти за рамки узкоспециализированных алгоритмов, предлагая основу для построения ИИ, способного к гибкому мышлению и эффективной адаптации к новым условиям. Успешная реализация данной концепции откроет возможности для применения искусственного интеллекта в разнообразных областях, от научных исследований и инженерных разработок до решения глобальных проблем, требующих комплексного анализа и нестандартных решений. В перспективе, подобные системы смогут не только выполнять заданные задачи, но и самостоятельно формулировать гипотезы, проводить эксперименты и извлекать знания из полученных результатов, приближая нас к созданию действительно интеллектуальных машин.
Наблюдения за развитием Empirical-MCTS неизбежно приводят к мысли о неизбежном техническом долге. Авторы предлагают механизм накопления опыта и эволюции мета-подсказок, позволяющий модели совершенствовать свои рассуждения без обновления параметров. Звучит элегантно, но любой инженер знает — рано или поздно, этот самый «опыт» превратится в сложный клубок зависимостей и краевых случаев. Как говорил Давид Гильберт: «В математике нет траекторий, есть только точки». В данном случае, каждая итерация обучения — это новая точка, а траектория к действительно устойчивой системе, способной к долгосрочному улучшению, представляется всё более туманной. Всё же, если система стабильно падает под нагрузкой, можно хотя бы сказать, что она последовательна.
Что Дальше?
Предложенный фреймворк Empirical-MCTS, безусловно, добавляет ещё один слой абстракции между языковой моделью и реальностью. Предположение о том, что накопление опыта в процессе поиска по дереву Монте-Карло решит проблему «галлюцинаций», наивно, но забавно. Продакшен, несомненно, найдёт способ сломать эту элегантную конструкцию, заставив модель «забывать» полезные паттерны или оптимизировать поиск в сторону тривиальных решений. CI, как всегда, станет храмом, где молимся, чтобы ничего не сломалось после очередного деплоя.
Настоящая проблема заключается не в улучшении процесса рассуждений, а в том, что сама постановка задачи часто является ошибочной. Бесконечное усложнение алгоритмов не компенсирует фундаментальную неопределённость и неполноту исходных данных. Эффективность, скорее всего, будет зависеть не от масштаба дерева поиска, а от качества мета-подсказок — а документация по ним, как известно, — миф, созданный менеджерами.
Вероятно, следующее поколение исследований сосредоточится на автоматическом обнаружении и исправлении ошибок в процессе рассуждений. Или, что более вероятно, на создании ещё более сложных систем накопления опыта, которые будут требовать ещё больше вычислительных ресурсов и ещё больше слоёв абстракции. Каждая «революционная» технология завтра станет техдолгом.
Оригинал статьи: https://arxiv.org/pdf/2602.04248.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Re:Zero — 4 сезон, 9 эпизод: Дата и время выхода.
- Лучшие шаблоны дивизий в Hearts Of Iron 4
- Шоу 911: Кто такой Рико Прием? Объяснение трибьюта Grip
- Все монгольские лагеря в Призраке Цусимы
- +1 DMG Per Revive Codes (June 2026)
- Лучшее ЛГБТК+ аниме, которое стоит посмотреть в месяц гордости
- Forza Horizon 6 Edogawa Baseball Stadium Location
- Throne And Liberty: Nightmare Deja Vu Moon Решение головоломки
- Решение головоломки с паролем Absolum в Yeldrim.
- 2-й сезон «Тайной магии» только что подарил отношениям Джинкс и Экко идеальный финал
2026-02-05 19:06