Автор: Денис Аветисян
Исследователи представили OdysseyArena — комплексную платформу для оценки способности ИИ-агентов к адаптации и решению сложных задач, требующих индуктивного мышления.
Купил акции по совету друга? А друг уже продал. Здесь мы учимся думать своей головой и читать отчётность, а не слушать советы.
Бесплатный телеграм-канал
OdysseyArena — это набор интерактивных сред для оценки возможностей больших языковых моделей в задачах, требующих долгосрочного планирования, активного взаимодействия и индуктивного рассуждения.
Несмотря на стремительное развитие больших языковых моделей (LLM), оценка их способности к автономному обучению и долгосрочному планированию остается сложной задачей. В работе ‘OdysseyArena: Benchmarking Large Language Models For Long-Horizon, Active and Inductive Interactions’ представлен новый комплекс интерактивных сред, предназначенный для всесторонней оценки индуктивных способностей и навыков долгосрочного взаимодействия LLM. Эксперименты с более чем 15 ведущими моделями показали существенный недостаток в способности к индуктивному решению задач, выявляя критическое ограничение в стремлении к автономному обучению в сложных условиях. Сможем ли мы преодолеть этот разрыв и создать LLM, способные к действительно автономному и проактивному решению проблем в динамичных средах?
Вызов Долгосрочного Рассуждения
Традиционные агенты искусственного интеллекта часто демонстрируют ограниченные возможности в решении задач, требующих длительной последовательной логической обработки информации. Исследования показывают, что при столкновении со сложными сценариями, требующими планирования на несколько шагов вперёд, такие системы склонны к зацикливанию и повторению одних и тех же действий. Эта проблема возникает из-за неспособности эффективно поддерживать и обновлять внутреннее представление о состоянии окружающей среды и последствиях своих действий в долгосрочной перспективе. В результате, вместо оптимального решения задачи, агент может бесконечно повторять одни и те же действия, не приближаясь к желаемому результату, что существенно ограничивает его применимость в реальных, динамичных условиях.
Успешная навигация в сложных и динамичных средах требует от систем искусственного интеллекта не просто мгновенной реакции на текущие события, но и активного исследования возможностей и стратегического предвидения. Вместо пассивного ответа на стимулы, продвинутые агенты должны уметь самостоятельно формировать цели, оценивать долгосрочные последствия своих действий и адаптироваться к меняющимся обстоятельствам. Такой подход подразумевает построение внутренних моделей окружения, планирование последовательности действий, направленных на достижение поставленных задач, и постоянную переоценку стратегии в свете новой информации. Способность к проактивному поведению, а не только к реагированию, является ключевым фактором для создания действительно интеллектуальных систем, способных эффективно функционировать в реальном мире.
Современные подходы к искусственному интеллекту, несмотря на успехи в решении узкоспециализированных задач, зачастую демонстрируют ограниченные возможности применительно к сложным, непредсказуемым ситуациям. Исследования показывают, что алгоритмы, эффективно работающие в простых, заранее определенных сценариях, терпят неудачу при столкновении с новыми, незнакомыми условиями. Этот пробел в способности к обобщению и адаптации указывает на существенные ограничения в долгосрочном планировании, подчеркивая необходимость разработки более гибких и универсальных систем, способных к самостоятельному обучению и принятию решений в динамично меняющемся окружении. Отсутствие надежных механизмов переноса знаний и навыков препятствует созданию интеллектуальных агентов, способных эффективно функционировать в реальном мире, где предсказать все возможные варианты развития событий практически невозможно.
OdysseyArena: Платформа для Надежной Оценки Агентов
OdysseyArena представляет собой набор интерактивных сред, предназначенных для всестороннего тестирования возможностей агентов в задачах, требующих долгосрочного планирования, активного взаимодействия со средой и индуктивного рассуждения. Данные среды построены таким образом, чтобы оценивать способность агентов к решению сложных задач, требующих не только непосредственного реагирования на текущие условия, но и прогнозирования будущих событий и адаптации стратегии на основе полученного опыта. Тестирование в OdysseyArena ориентировано на оценку способности агентов к обобщению знаний и применению их в новых, незнакомых ситуациях, что критически важно для разработки действительно интеллектуальных систем.
Платформа OdysseyArena обеспечивает поддержку различных динамик окружения для всесторонней оценки агентов. Это включает в себя дискретные латентные правила, определяющие поведение окружения на основе скрытых состояний; непрерывную стохастическую динамику, моделирующую процессы с элементами случайности и непрерывными изменениями параметров; и периодические временные закономерности, представляющие циклически повторяющиеся события и состояния. Комбинация этих типов динамик позволяет тестировать способность агентов адаптироваться к различным условиям и выявлять ограничения существующих алгоритмов в задачах с долгосрочным планированием и активным взаимодействием со средой.
OdysseyArena предоставляет два режима оценки агентов: OdysseyArena-Lite и OdysseyArena-Challenge. OdysseyArena-Lite представляет собой стандартизированный набор окружений, предназначенный для быстрой и эффективной оценки базовых возможностей агентов. В то время как OdysseyArena-Lite фокусируется на скорости оценки, OdysseyArena-Challenge ставит агентов в более сложные условия, ограничивая количество шагов до 1000 и более. Это позволяет оценить стабильность рассуждений агента в задачах, требующих долгосрочного планирования и адаптации к изменяющейся среде, выявляя потенциальные недостатки в логике принятия решений при ограниченных ресурсах и увеличении сложности задачи.
На платформе OdysseyArena модель Gemini 3 Pro Preview продемонстрировала наивысший показатель успешности — 44.17%. Этот результат является на текущий момент передовым и свидетельствует о значительном прогрессе в области разработки агентов, способных к сложным рассуждениям и долгосрочному планированию. Указанный показатель был достигнут в рамках тестов, направленных на оценку способностей агентов к решению задач, требующих активного взаимодействия с окружением и применения индуктивного мышления.
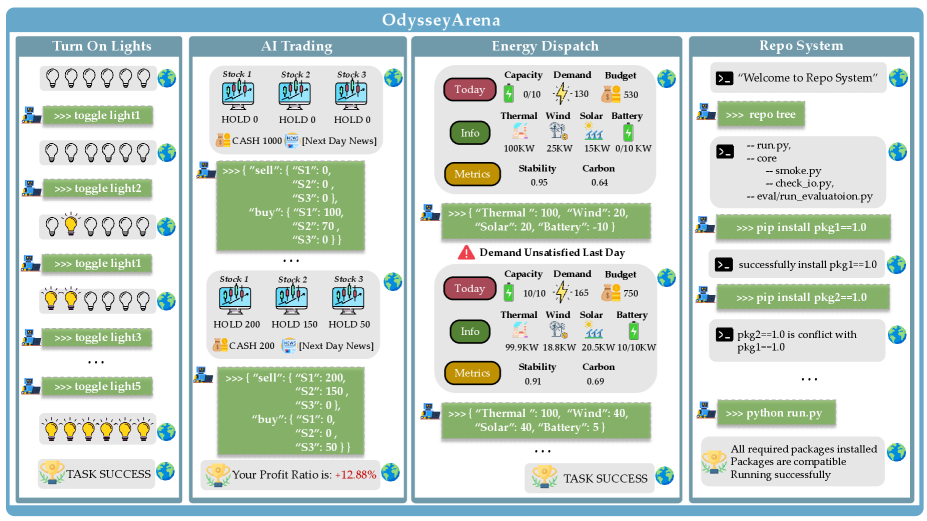
Разнообразие Окружений, Общие Принципы: Основная Динамика
Среда ‘Turn On Lights’ построена на основе дискретных скрытых правил, что требует от агента вывода булевой логики для достижения поставленных целей. В частности, успешное выполнение задачи подразумевает определение логических связей между различными переключателями и источниками света, где каждый переключатель представляет собой булеву переменную, определяющую состояние освещения. Агент должен научиться определять, какие комбинации переключателей приводят к желаемому результату, эффективно реализуя логические операции ‘И’, ‘ИЛИ’ и ‘НЕ’ для управления состоянием освещения. Сложность заключается в том, что эти правила не заданы явно и должны быть выведены агентом путем взаимодействия со средой и анализа наблюдаемых результатов.
Среда ‘AI Trading’ моделирует непрерывную стохастическую динамику, представляя собой симуляцию финансовых рынков с элементами случайности. Агенты сталкиваются с необходимостью управления рисками и неопределенностью в условиях колебаний цен и объемов торгов. В отличие от дискретных сред, где решения принимаются на основе четких правил, ‘AI Trading’ требует от агентов оценки вероятностей и принятия решений в условиях неполной информации. Динамика среды определяется случайными процессами, имитирующими рыночный шум и непредсказуемость, что требует от агентов адаптации стратегий для максимизации прибыли и минимизации потерь в условиях высокой волатильности.
Окружение ‘Energy Dispatch’ моделирует периодические временные закономерности, предъявляя к агентам требования по предвидению и адаптации к циклическим потребностям в ресурсах. Это означает, что спрос на энергию изменяется предсказуемым образом во времени — например, пики потребления в определенные часы суток или дни недели. Агенты должны анализировать эти периодические колебания и соответствующим образом планировать распределение ресурсов, чтобы обеспечить стабильное энергоснабжение и минимизировать издержки. Эффективное управление в данном окружении требует от агентов способности к экстраполяции временных рядов и прогнозированию будущих потребностей на основе исторических данных.
Окружение ‘Repo System’ моделирует систему управления программными пакетами, используя реляционные графовые структуры данных. Каждый программный пакет представлен узлом графа, а зависимости между пакетами — ребрами. Это позволяет имитировать сложные взаимосвязи, характерные для реальных систем управления пакетами, где установка или обновление одного пакета может потребовать установки или обновления других пакетов, что создает каскад зависимостей. Агенту необходимо эффективно решать задачи, связанные с установкой, удалением и обновлением пакетов, учитывая эти зависимости, чтобы избежать конфликтов и обеспечить стабильность системы. Структура графа позволяет моделировать как прямые, так и косвенные зависимости, что значительно усложняет задачу для агента.
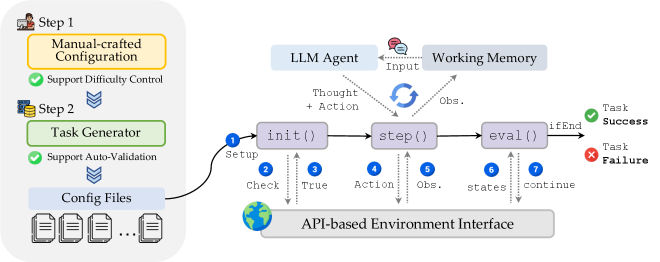
LLM-Агенты как Испытательная Платформа для Долгосрочного Рассуждения
В рамках исследования OdysseyArena активно используются агенты, основанные на больших языковых моделях (LLM), как мощная платформа для изучения долгосрочного рассуждения. Эти агенты позволяют исследовать сложные сценарии, требующие планирования и принятия решений на протяжении длительных периодов времени. Их способность к активному поиску решений и индуктивным умозаключениям делает LLM-агентов уникальным инструментом для моделирования и анализа процессов, где необходимо прогнозирование последствий действий и адаптация к изменяющимся условиям. Использование LLM-агентов предоставляет возможность детально изучить механизмы долгосрочного планирования и выявить факторы, влияющие на успешное выполнение задач в сложных интерактивных средах.
Агенты на базе больших языковых моделей (LLM) продемонстрировали значительную способность к активному исследованию окружающей среды и индуктивному мышлению, что является ключевым фактором для успешной навигации в сложных условиях. В процессе взаимодействия с ареной OdysseyArena, эти агенты не просто выполняют заданные инструкции, но и самостоятельно ищут новые пути решения задач, адаптируясь к меняющимся обстоятельствам. Индуктивное мышление позволяет им обобщать полученный опыт и применять его к новым, ранее не встречавшимся ситуациям, эффективно извлекая уроки из каждого взаимодействия. Эта комбинация активного поиска и способности к обобщению позволяет LLM-агентам не просто решать текущие задачи, но и развивать стратегии для преодоления более сложных, долгосрочных препятствий, что делает их ценным инструментом для изучения процессов рассуждения и обучения в искусственном интеллекте.
Эффективность агентов, основанных на больших языковых моделях (LLM), напрямую зависит от тщательно разработанной функции вознаграждения, которая служит компасом в процессе обучения и определяет их поведение. Данная функция не просто оценивает успех или неудачу, но и формирует стратегию действий агента, направляя его к оптимальным решениям в сложных сценариях. Неудачно спроектированная функция вознаграждения может привести к нежелательному поведению, такому как зацикливание на повторяющихся действиях или игнорирование долгосрочных целей. Поэтому, оптимизация функции вознаграждения является ключевым аспектом разработки LLM-агентов, способных эффективно решать задачи, требующие долгосрочного планирования и индуктивного мышления, и позволяет им адаптироваться к меняющимся условиям окружающей среды.
Анализ поведения агентов, функционирующих на базе больших языковых моделей, позволяет оценить их способность преодолевать трудности и избегать зацикливания на повторяющихся действиях. Эффективность решения задач, требующих долгосрочного планирования и индуктивного мышления, напрямую связана с тем, насколько успешно агент избегает подобных “петли повторений”. Для количественной оценки этой способности используется метрика — “Коэффициент зацикливания” (Loop Ratio). Высокое значение данного коэффициента указывает на неэффективность стратегии агента, его склонность к повторению одних и тех же действий без достижения прогресса в решении поставленной задачи, что существенно ограничивает возможности агента в сложных средах, требующих последовательного планирования и адаптации.
Высокий коэффициент повторения действий (Loop Ratio) является чётким индикатором неэффективности агента в решении задач, требующих долгосрочного планирования и индуктивного рассуждения. Постоянное возвращение к одним и тем же действиям свидетельствует о неспособности агента адаптироваться к изменяющимся условиям среды и находить оптимальные стратегии для достижения поставленной цели. Такое поведение не позволяет агенту эффективно исследовать окружающее пространство и выявлять скрытые закономерности, необходимые для успешного решения сложных задач, требующих последовательного применения логических выводов на протяжении длительного времени. В конечном итоге, высокий Loop Ratio существенно ограничивает возможности агента в решении задач, требующих не только непосредственного реагирования на текущую ситуацию, но и предвидения последствий своих действий на отдалённую перспективу.
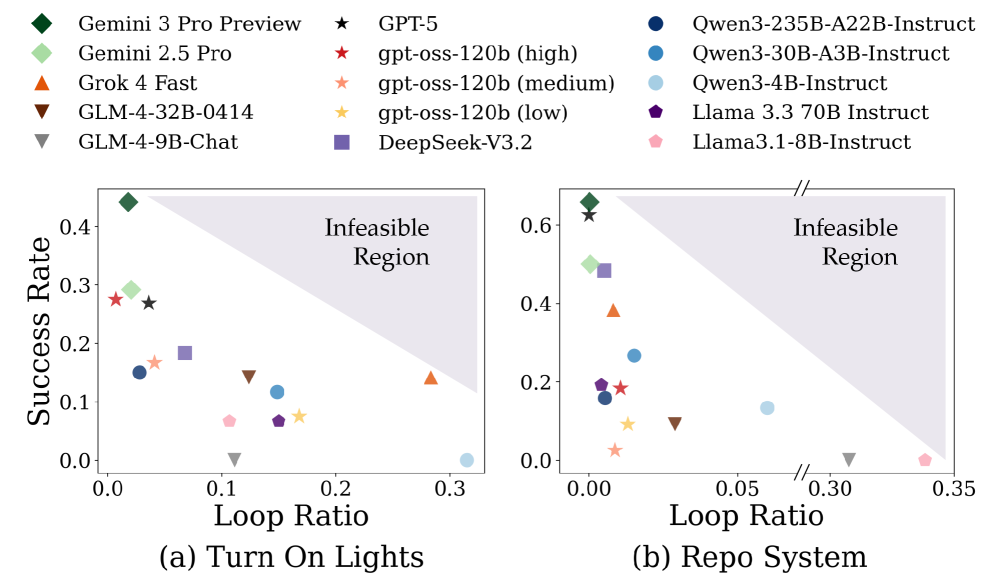
Исследование, представленное в данной работе, акцентирует внимание на существенном разрыве между современными большими языковыми моделями и человеческим уровнем рассуждений, особенно в контексте долгосрочных, активных и индуктивных взаимодействий. Данный подход к оценке, реализованный в OdysseyArena, требует от агентов не просто выдавать ответы, но и демонстрировать способность к обобщению и адаптации в динамической среде. Как однажды заметил Дональд Кнут: «Преждевременная оптимизация — корень всех зол». Аналогично, в контексте разработки агентов, стремление к немедленным результатам без глубокого понимания принципов индуктивного мышления может привести к поверхностным решениям, неспособным к надежной работе в сложных сценариях. Акцент на проверяемой корректности, а не на эвристиках, является ключевым для создания действительно интеллектуальных систем.
Куда же дальше?
Представленная работа выявляет не столько недостатки текущих больших языковых моделей, сколько закономерные ограничения подхода, основанного исключительно на статистическом моделировании. OdysseyArena, как инструмент оценки индуктивного рассуждения, демонстрирует, что способность «решать» задачи в обучающей выборке не гарантирует обобщение на новые, требующие активного взаимодействия и логической дедукции. Это, конечно, не открытие века, но наглядное подтверждение необходимости перехода от простого увеличения объёма данных к разработке принципиально новых алгоритмов.
Очевидно, что будущее исследований лежит в области формализации процесса индукции. Недостаточно просто «научить» модель различать закономерности; необходимо, чтобы она могла доказывать их истинность, а не просто демонстрировать высокую точность на тестовом наборе. Разработка формальных систем представления знаний и алгоритмов логического вывода, способных эффективно взаимодействовать с языковыми моделями, представляется задачей, требующей немедленного внимания.
Возможно, истинная элегантность искусственного интеллекта проявится не в способности имитировать человеческий разум, а в способности превзойти его в областях, требующих абсолютной логической строгости. И тогда, возможно, оценка моделей перестанет сводиться к сравнению с человеческими показателями, а будет основываться на математической чистоте и доказуемости их решений.
Оригинал статьи: https://arxiv.org/pdf/2602.05843.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Лучшие шаблоны дивизий в Hearts Of Iron 4
- Решение головоломки с паролем Absolum в Yeldrim.
- Шоу 911: Кто такой Рико Прием? Объяснение трибьюта Grip
- Прохождение квеста Miles Apart в NTE (Neverness to Everness)
- Лучшие чертежи Factorio 2.0 | Факторио Космическая эра
- Мальчики: Объяснение сцены с фейерверком и молоком (смотреть полную сцену)
- Доллар обгонит вьетнамский донг? Эксперты раскрыли неожиданный сценарий
- Как создать свечи в Enshrouded
- Все правильные ответы на тест Ghost Station в Neverness to Everness
- Раскрытие удивительных истин о «Доме Давида» на Амазонке!
2026-02-08 20:44