Автор: Денис Аветисян
Исследователи представляют TIME — комплексный бенчмарк, призванный поднять планку для оценки моделей прогнозирования временных рядов нового поколения.
Купил акции по совету друга? А друг уже продал. Здесь мы учимся думать своей головой и читать отчётность, а не слушать советы.
Бесплатный телеграм-канал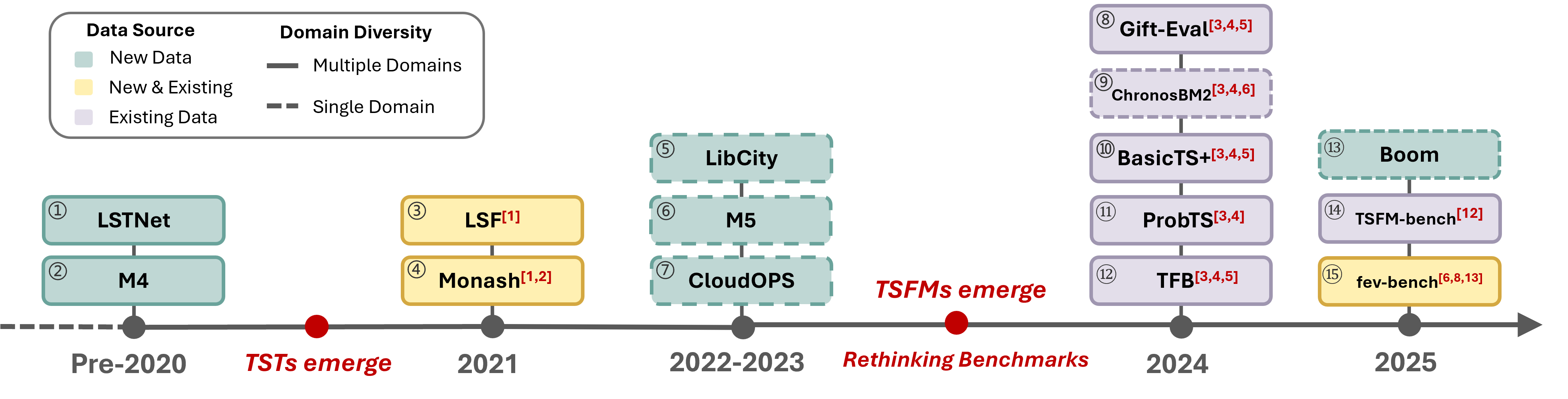
Представлен бенчмарк TIME, обеспечивающий более качественные данные, согласованность задач и оценку на уровне паттернов для моделей прогнозирования временных рядов.
Существующие бенчмарки для оценки моделей прогнозирования временных рядов зачастую страдают от недостаточной целостности данных и оторванности от реальных задач. В работе ‘It’s TIME: Towards the Next Generation of Time Series Forecasting Benchmarks’ представлен TIME — новый, ориентированный на задачи бенчмарк, включающий 50 свежих наборов данных и 98 задач прогнозирования, разработанный для строгой оценки моделей-оснований в условиях нулевой передачи данных. TIME использует человеко-машинный подход к построению, обеспечивая высокое качество данных и согласованность задач с реальными потребностями, а также предлагает новый уровень анализа, основанный на паттернах временных рядов, а не на статических метках. Позволит ли TIME более объективно оценить потенциал моделей-оснований и ускорить прогресс в области прогнозирования временных рядов?
Выявление Ложных Утверждений в Прогнозировании Временных Рядов
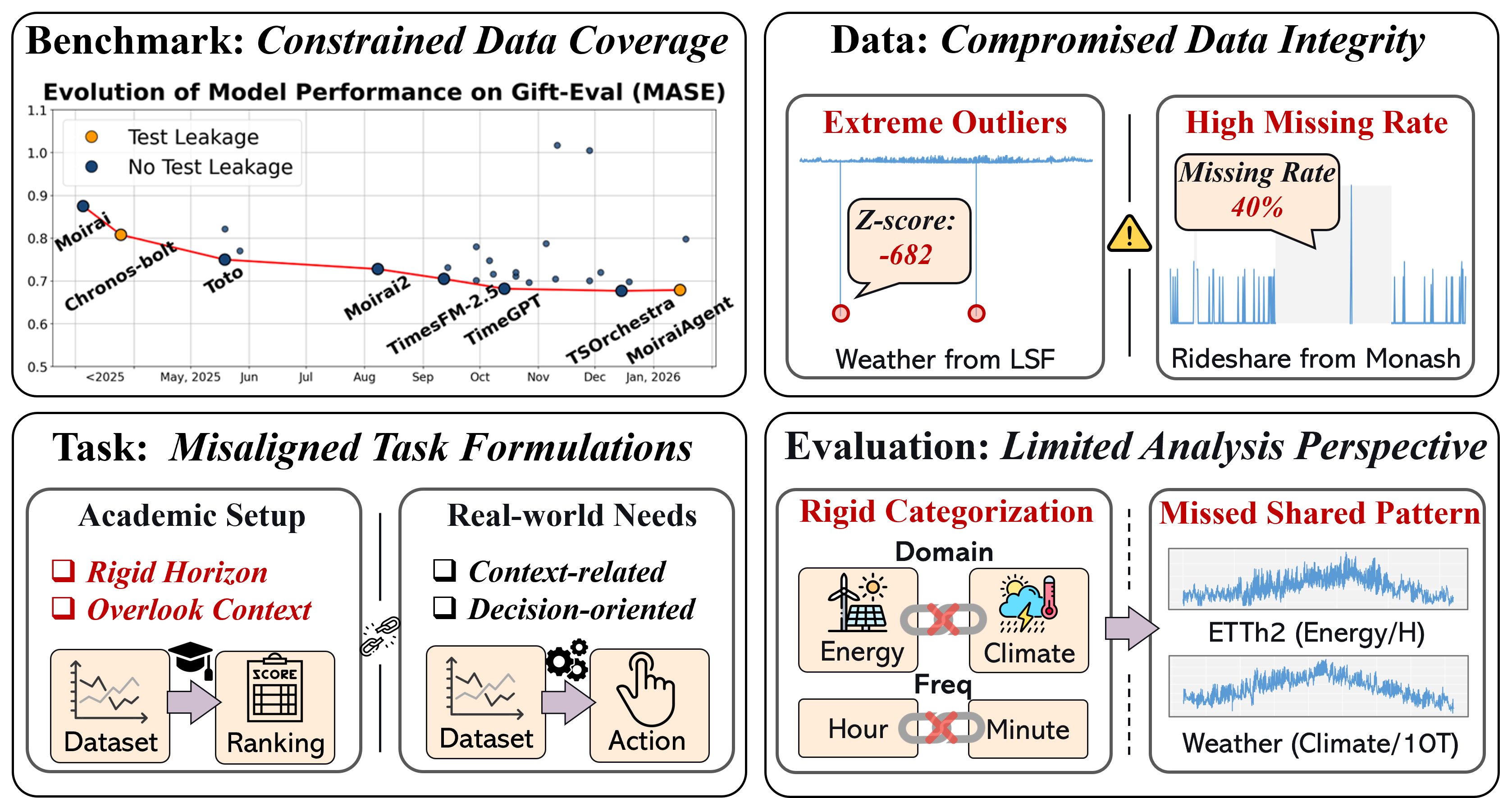
Традиционные бенчмарки для прогнозирования временных рядов часто страдают от утечки данных, что приводит к завышенным и ненадежным оценкам производительности. Данная проблема возникает, когда информация из будущих периодов, предназначенная для тестирования, неявно попадает в обучающую выборку, создавая иллюзию высокой точности модели. Это может произойти из-за неправильной обработки данных, использования будущих значений в качестве признаков или недостаточной изоляции обучающих и тестовых наборов. В результате, опубликованные результаты могут значительно отличаться от реальной производительности модели на новых, ранее не встречавшихся данных, что затрудняет объективное сравнение различных методов и замедляет прогресс в области анализа временных рядов. Крайне важно выявлять и устранять утечку данных для обеспечения достоверности оценок и продвижения действительно эффективных моделей.
Загрязнение данных в обучающих выборках происходит, когда информация, предназначенная для оценки модели на тестовом наборе, непреднамеренно включается в процесс обучения. Это создает искусственно завышенную оценку возможностей модели, поскольку она уже «видела» часть данных, на которых должна быть проверена. В результате, заявленная точность прогнозирования оказывается нереалистичной и не отражает фактическую способность модели обобщать информацию на новых, ранее не встречавшихся временных рядах. Подобное искажение может привести к ошибочным выводам о прогрессе в области анализа временных рядов и затруднить разработку действительно надежных и эффективных моделей прогнозирования.
Для реального прогресса в анализе временных рядов необходимы строгие и незагрязненные эталоны оценки. Существующие подходы часто страдают от утечки данных, когда информация из будущего, предназначенная для тестирования, неявно попадает в обучающую выборку, что приводит к завышенным и нереалистичным показателям эффективности моделей. Это искажает истинную картину возможностей алгоритмов и препятствует разработке действительно надежных и обобщающих решений. Поэтому, создание тщательно проверенных и изолированных наборов данных для тестирования является критически важным шагом для объективной оценки и дальнейшего развития методов прогнозирования временных рядов, позволяя отличить реальные улучшения от ложных результатов.
TIME: Новый Эталон для Оценки Сложных Задач Прогнозирования
Бенчмарк TIME представляет собой новую, ориентированную на задачи платформу оценки, разработанную для устранения ограничений существующих бенчмарков. В отличие от традиционных подходов, фокусирующихся на отдельных метриках или упрощенных сценариях, TIME оценивает модели в контексте комплексных, реалистичных задач, требующих последовательного выполнения нескольких шагов. Это достигается за счет использования тщательно разработанных сценариев, которые моделируют реальные пользовательские взаимодействия и позволяют оценить не только точность, но и эффективность, надежность и обобщающую способность моделей в сложных условиях. Ключевым отличием является акцент на функциональности, а не просто на производительности отдельных компонентов.
Тщательная курация данных является ключевым элементом TIME Benchmark. Для создания разнообразных и репрезентативных наборов данных используется, в частности, метод понижения дискретизации (downsampling). Этот метод позволяет уменьшить объем данных, сохраняя при этом их статистические свойства и обеспечивая более эффективное обучение и оценку моделей. Понижение дискретизации применяется для балансировки классов, уменьшения вычислительных затрат и повышения обобщающей способности моделей, особенно в сценариях с ограниченными ресурсами или несбалансированными данными. Применение downsampling в TIME Benchmark гарантирует, что результаты оценки моделей будут более надежными и отражают их реальную производительность на разнообразных данных.
Бенчмарк TIME поддерживает оценку в условиях нулевого обучения (zero-shot evaluation), что позволяет оценить способность моделей к обобщению на новые, ранее не встречавшиеся данные без какой-либо дополнительной адаптации или тонкой настройки под конкретную задачу. В рамках данного подхода модели оцениваются на задачах, для которых они не получали специализированного обучения, что позволяет выявить их истинный уровень понимания и способности к переносу знаний. Это достигается за счет использования набора задач и данных, отличных от тех, на которых модели были предварительно обучены, и измерения их производительности без предоставления каких-либо примеров или инструкций, специфичных для целевой задачи.
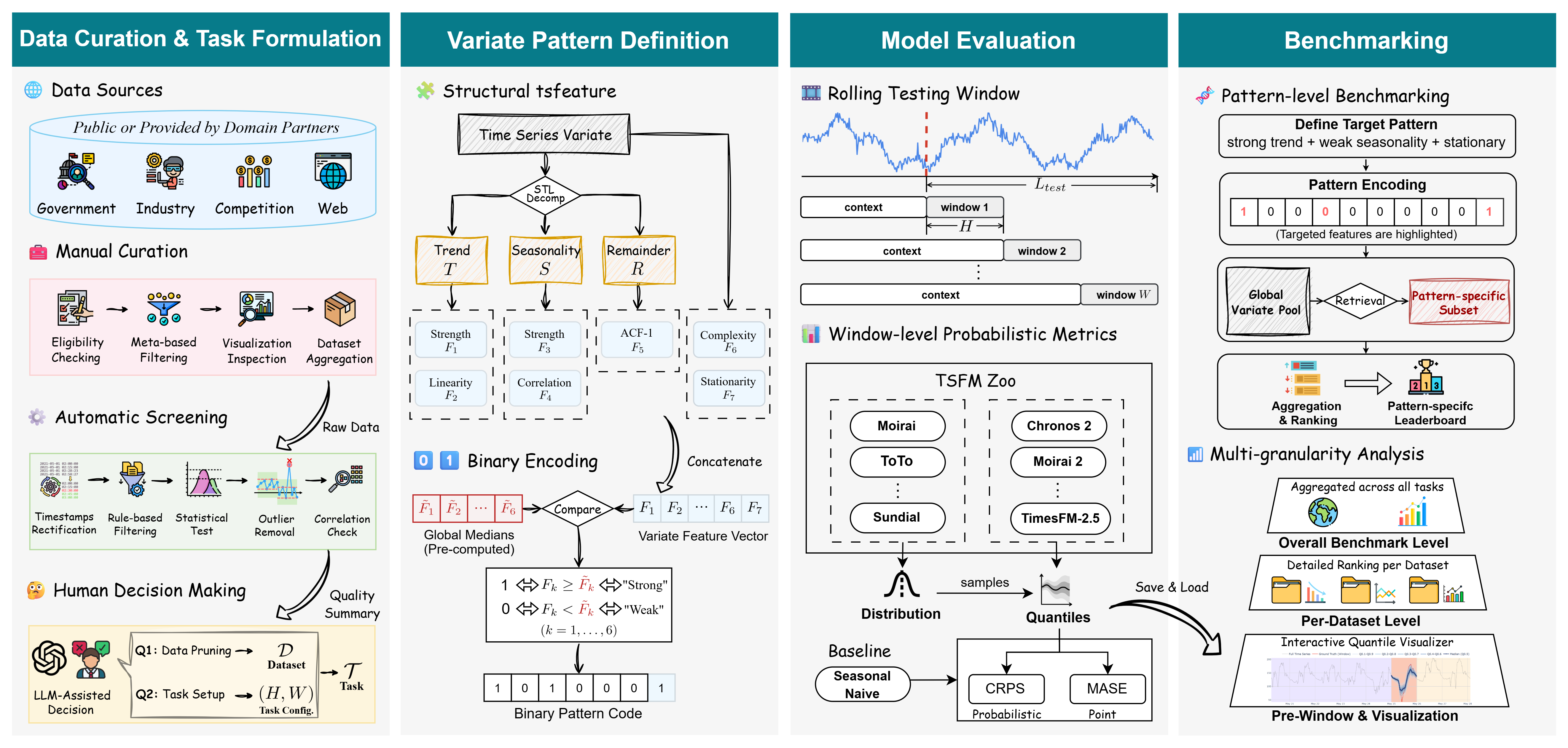
Детализированный Анализ на Уровне Паттернов для Объективной Оценки
В отличие от традиционных сводных метрик, эталон TIME использует анализ на уровне паттернов (Pattern-Level Analysis) для оценки производительности моделей временных рядов на основе конкретных характеристик данных. Этот подход позволяет перейти от общей оценки к детализированному анализу, выявляя, как модели справляются с различными особенностями временных рядов, такими как тренды и сезонность. Такой уровень гранулярности позволяет более точно определить сильные и слабые стороны моделей, а также выявить потенциальные смещения, которые могут быть скрыты при использовании агрегированных показателей.
Для анализа временных рядов в TIME benchmark применяется метод разложения STL (Seasonal and Trend decomposition using Loess), позволяющий выделить компоненты тренда и сезонности. Разложение STL представляет собой аддитивную модель, где исходный временной ряд представляется как сумма тренда, сезонности и остаточной компоненты. Оценка силы тренда и сезонности производится на основе амплитуды соответствующих компонентов. Использование STL позволяет изолировать и количественно оценить вклад каждого компонента в общую динамику временного ряда, что необходимо для более детального анализа производительности моделей на различных типах временных рядов.
Анализ структурных признаков временных рядов выявил значения Fisher Score в диапазоне от 1.19 до 4.46, что демонстрирует высокую дискриминационную способность и значительно превышает пороговое значение 0.25. Параллельно, рассчитанные значения Cohen’s d варьируются от 1.54 до 2.98, указывая на наличие больших эффектов. Данные показатели подтверждают, что используемые признаки эффективно различают различные типы временных рядов и обладают статистически значимой способностью к разделению классов.
Анализ производительности моделей временных рядов на основе выделенных паттернов позволяет получить детальное представление об их сильных и слабых сторонах, а также выявить потенциальные смещения. Используемые признаки, характеризующие тренд и сезонность, демонстрируют низкую или умеренную корреляцию (менее 0.7), что подтверждает их взаимодополняемость и независимость в описании различных характеристик временных рядов. Это позволяет более точно оценить, на каких типах данных модель показывает лучшие результаты, а где требуется дополнительная оптимизация или адаптация.
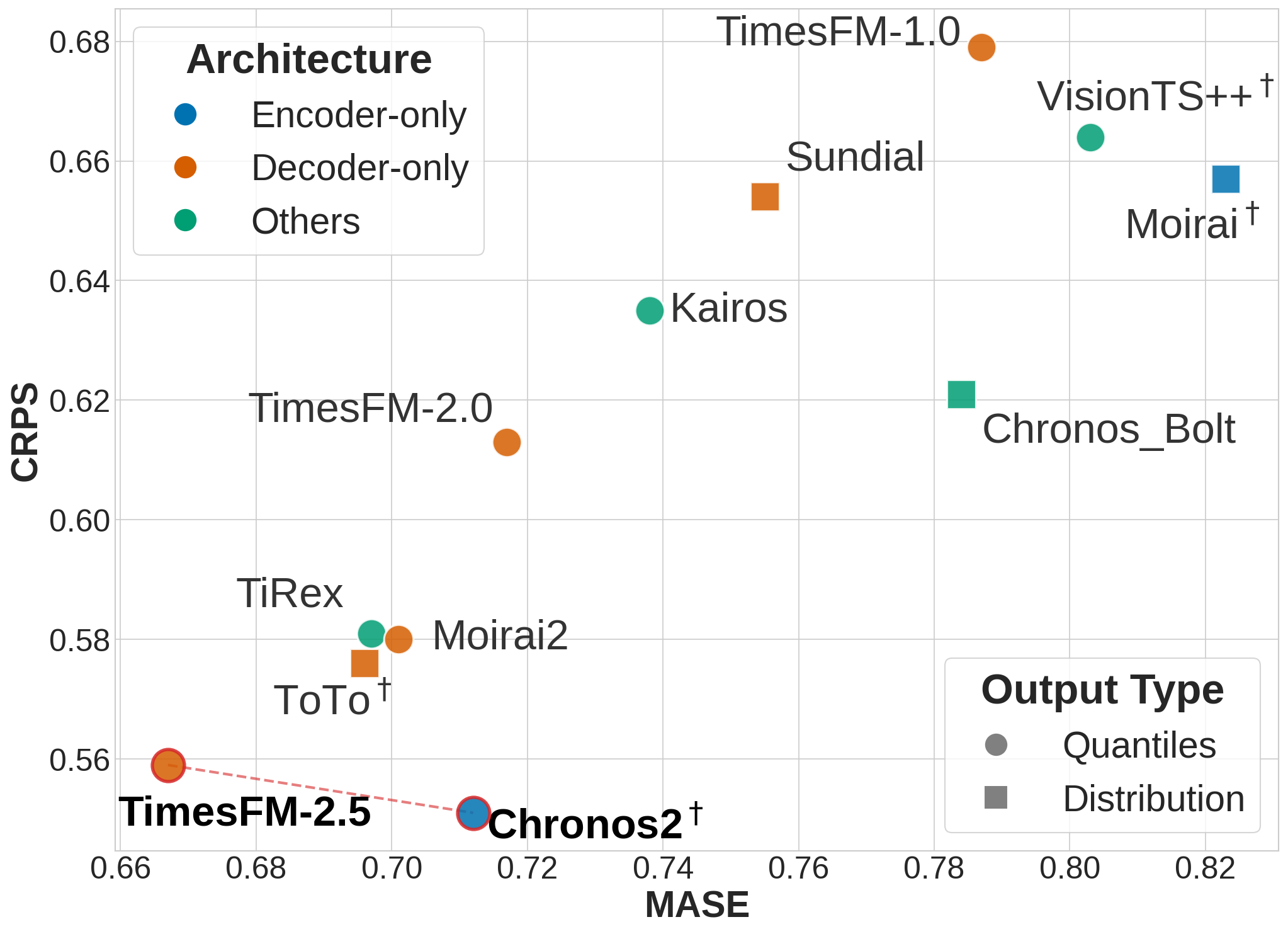
Оценка Надежности и Устойчивости Моделей Прогнозирования Временных Рядов
Оценка моделей временных прогнозирования (TSFM) в рамках эталона TIME осуществляется с использованием метрик, позволяющих количественно оценить точность прогнозов. В частности, метрика MASE (Mean Absolute Scaled Error) измеряет среднюю абсолютную ошибку, масштабированную относительно наивного прогноза, что обеспечивает сопоставимость результатов для различных временных рядов. В то же время, метрика CRPS (Continuous Ranked Probability Score) оценивает качество вероятностных прогнозов, учитывая не только точность предсказания, но и уверенность модели в этом предсказании. Комбинация этих метрик позволяет всесторонне оценить производительность TSFM, выявляя сильные и слабые стороны различных моделей и подходов к прогнозированию.
Оценка моделей временных прогнозов, проводимая в рамках бенчмарка TIME, выявила, что проблемы разреженности данных могут существенно влиять на способность моделей к обобщению. Анализ по отдельным паттернам показал, что модели, такие как Chronos2 и TimesFM 2.5, демонстрируют устойчиво высокие результаты по показателям CRPS (Continuous Ranked Probability Score) и MASE (Mean Absolute Scaled Error) в различных сценариях. Это свидетельствует о более эффективной обработке неполных данных и лучшей способности к прогнозированию в условиях ограниченной информации, что крайне важно для практического применения моделей временных прогнозов в реальных задачах.
Тщательное тестирование, подобное тому, что предоставляет бенчмарк TIME, является критически важным для подтверждения надежности и достоверности моделей временных прогнозов (TSFM) при их применении в реальных задачах. Оценка производительности на разнообразных наборах данных позволяет выявить потенциальные уязвимости и ограничения, гарантируя, что модель способна давать точные прогнозы даже в сложных и непредсказуемых условиях. Отсутствие всесторонней проверки может привести к ошибочным результатам и неверным решениям, поэтому строгий контроль качества и объективная оценка являются необходимыми условиями для успешного внедрения TSFM в практические приложения, будь то прогнозирование спроса, управление ресурсами или анализ финансовых рынков.
В основе любого эффективного прогнозирования временных рядов лежит строгое определение задачи. Работа, представленная в статье, подчеркивает необходимость в качественных данных и согласованности задач для оценки фундаментальных моделей. Как однажды заметил Кен Томпсон: «В программировании, как и в математике, красота кроется в простоте и точности». Это утверждение полностью соответствует подходу, описанному в статье, где акцент делается на анализ на уровне паттернов и создание надежных критериев оценки. Без четкого понимания цели, любые вычислительные усилия становятся бессмысленным шумом, а предсказания — случайными колебаниями.
Что дальше?
Представленная работа, хотя и представляет собой значительный шаг вперед в оценке моделей прогнозирования временных рядов, не решает фундаментальную проблему: истинная проверка — это не демонстрация работоспособности на ограниченном наборе данных, а математическое доказательство корректности алгоритма. Создание набора данных, лишенного скрытых смещений и отражающего все разнообразие реальных временных рядов, — задача, возможно, недостижимая в принципе. Любой набор данных, каким бы тщательно он ни был подобран, всегда будет лишь аппроксимацией реальности.
Настоящий прогресс, следовательно, заключается не в создании все более масштабных бенчмарков, а в разработке методов формальной верификации моделей. Необходимо перейти от эмпирических оценок к доказательствам с использованием строгой математической логики. Акцент на анализе паттернов — это, безусловно, полезное направление, но лишь в том случае, если эти паттерны определены аксиоматически и их свойства строго доказаны.
Иначе, мы обречены на бесконечный цикл улучшения моделей, которые “хорошо работают” на тестах, но могут дать катастрофические результаты в условиях, отличных от тестовых. Элегантность решения заключается не в его способности обмануть метрику, а в его внутренней согласованности и математической чистоте. Именно этого, а не просто более высоких чисел на графиках, должно добиваться научное сообщество.
Оригинал статьи: https://arxiv.org/pdf/2602.12147.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Re:Zero — 4 сезон, 9 эпизод: Дата и время выхода.
- Лучшие шаблоны дивизий в Hearts Of Iron 4
- Шоу 911: Кто такой Рико Прием? Объяснение трибьюта Grip
- Re:Zero Сезон 4, Выпуск 10 Дата и Время выхода
- Лучшее ЛГБТК+ аниме, которое стоит посмотреть в месяц гордости
- Forza Horizon 6 Edogawa Baseball Stadium Location
- Все монгольские лагеря в Призраке Цусимы
- Throne And Liberty: Nightmare Deja Vu Moon Решение головоломки
- Трон и свобода: локация «Сокровища рассвета»
- Список всех команд консоли администратора Soulmask
2026-02-15 17:36