Автор: Денис Аветисян
Новое исследование показывает, что даже высокоточные языковые модели демонстрируют систематические разногласия, способные привести к противоречивым научным выводам.
Купил акции по совету друга? А друг уже продал. Здесь мы учимся думать своей головой и читать отчётность, а не слушать советы.
Бесплатный телеграм-канал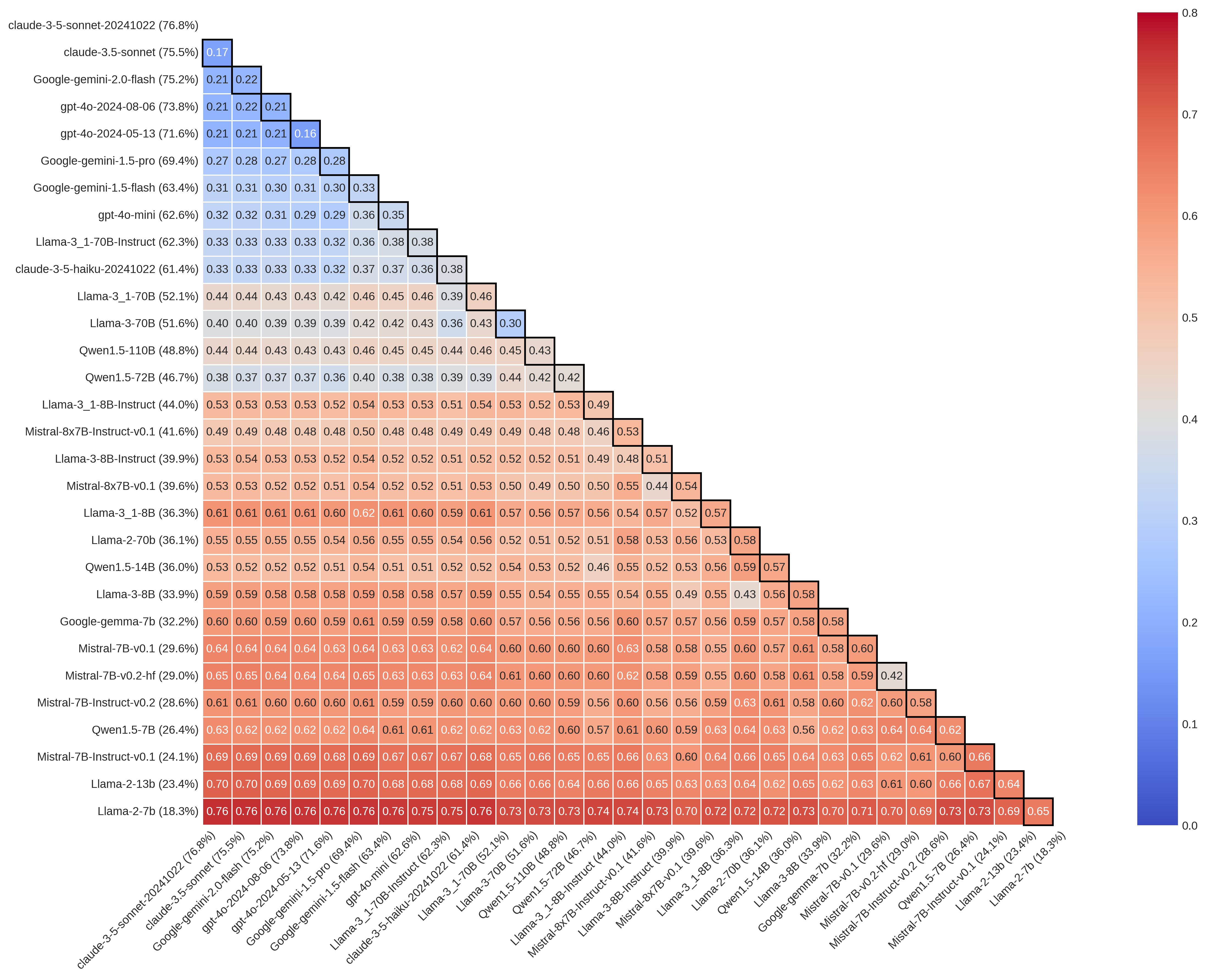
Работа выявляет ‘иллюзию бенчмарка’, заключающуюся в несоответствии между высокой производительностью моделей на стандартных тестах и их фактической надежностью в научных исследованиях, а также поднимает вопросы о воспроизводимости результатов, полученных с использованием ИИ.
Несмотря на кажущуюся сходимость в оценках качества больших языковых моделей (LLM), их внутренние расхождения могут скрывать глубокие эпистемические разногласия. В своей работе ‘Benchmark Illusion: Disagreement among LLMs and Its Scientific Consequences’ авторы исследуют этот феномен, демонстрируя, что даже LLM с сопоставимой производительностью на бенчмарках MMLU-Pro и GPQA расходятся в ответах на 16-66% вопросов. Эти расхождения приводят к различным профилям ошибок и, как следствие, к непоследовательным научным выводам при использовании LLM для аннотации данных и проведения исследований — изменение модели аннотации может приводить к изменению эффекта обработки на 80% и даже к изменению его знака. Не является ли эта «иллюзия бенчмарка» серьезной угрозой воспроизводимости научных результатов, полученных с использованием LLM?
Иллюзия Точности в Научном Познании
В последнее время наблюдается стремистый рост применения больших языковых моделей (БЯМ) в различных областях науки, от анализа геномных данных до разработки новых материалов. Однако, несмотря на впечатляющие возможности этих моделей в обработке и генерации текста, их надежность в контексте научных исследований вызывает обоснованные опасения. В отличие от традиционных алгоритмов, БЯМ, обученные на огромных объемах данных, могут генерировать правдоподобные, но при этом неверные или вводящие в заблуждение результаты, особенно при работе с узкоспециализированной научной информацией. Недостаточная прозрачность процесса принятия решений этими моделями и сложность проверки достоверности полученных выводов требуют осторожного подхода к их использованию и разработки методов оценки надежности, чтобы избежать распространения ложных научных утверждений.
Распространенное предположение о том, что высокая производительность языковых моделей на стандартных наборах данных автоматически гарантирует надежность научных выводов, может оказаться опасным упрощением. Исследования показывают, что модели, демонстрирующие впечатляющие результаты при решении задач в контролируемой среде бенчмарков, часто демонстрируют значительные расхождения и неточности при применении к реальным научным проблемам. Это несоответствие обусловлено тем, что бенчмарки, как правило, не отражают всю сложность и неоднозначность реальных научных данных, а также не учитывают необходимость критического мышления и интерпретации результатов, что приводит к переоценке фактических возможностей модели в контексте научных исследований.
Раскрытие Систематических Ошибок: За Пределами Случайного Шума
В отличие от случайных ошибок, которые возникают непредсказуемо и усредняются при большом количестве повторений, большие языковые модели (LLM) подвержены систематическим ошибкам — последовательным отклонениям, коррелирующим с определенными условиями ввода или структурой модели. Эти ошибки не являются просто шумом, а представляют собой устойчивые смещения, проявляющиеся в предсказуемых паттернах неточностей. Например, модель может демонстрировать систематическую склонность к определенным ответам в зависимости от тона запроса, сложности вопроса или даже демографических характеристик, закодированных в обучающих данных. Важно отметить, что систематические ошибки сохраняются даже при увеличении объема данных или повторных запусках модели, что отличает их от случайных колебаний.
Исследования, использующие «Фреймворк ошибок измерений» (Measurement Error Framework), предоставляют статистические инструменты для анализа и количественной оценки систематических искажений в ответах больших языковых моделей (LLM). В отличие от случайных ошибок, которые являются непредсказуемыми отклонениями, эти фреймворки позволяют выявить устойчивые смещения, коррелирующие с определенными входными данными или условиями. Применяемые методы, такие как анализ дисперсии и регрессионный анализ, демонстрируют, что эти смещения не являются случайным шумом, а представляют собой структурные недостатки, заложенные в процессе обучения или архитектуре модели. Количественная оценка этих систематических ошибок позволяет оценить их влияние на надежность и справедливость результатов, полученных с помощью LLM.
Регрессионный анализ позволяет моделировать систематические ошибки в работе больших языковых моделей (LLM), однако необходимо учитывать возможность получения искаженных результатов. Использование предвзятых данных для обучения регрессионной модели приведет к воспроизведению и усилению этих же предвзятостей в оценках. Кроме того, неверные предположения о структуре данных или выборе подходящей регрессионной функции могут существенно повлиять на точность выявления и количественной оценки систематических ошибок. Важно критически оценивать как входные данные, так и применяемые методы регрессионного анализа для обеспечения достоверности полученных результатов и избежания ложных выводов о производительности LLM.
Роль Аннотации и Конструирования Бенчмарков
Процесс аннотирования, заключающийся в разметке данных для обучения больших языковых моделей (LLM), подвержен субъективным искажениям и несогласованности. Данные, размеченные разными аннотаторами, могут отличаться из-за различий в интерпретации инструкций или личных предубеждений, что приводит к неточностям в обучающем наборе. Эти несоответствия напрямую влияют на производительность LLM, снижая точность, надежность и обобщающую способность модели. Несогласованность в аннотациях может проявляться в различных формах, включая расхождения в категоризации, оценке релевантности или определении границ сущностей, что в конечном итоге негативно сказывается на качестве обученной модели.
Исследования Ким и др. (2021) и Розенаса и Стукала (2019) однозначно демонстрируют влияние качества аннотаций на результаты обучения и работы языковых моделей. В частности, было установлено, что неточности, противоречия и субъективность в процессе разметки данных напрямую коррелируют со снижением производительности модели, а также с увеличением количества ошибок в ее предсказаниях. В работах подчеркивается, что даже незначительные расхождения в аннотациях могут приводить к существенным изменениям в поведении модели, что делает обеспечение высокого качества разметки критически важным этапом при создании и оценке больших языковых моделей.
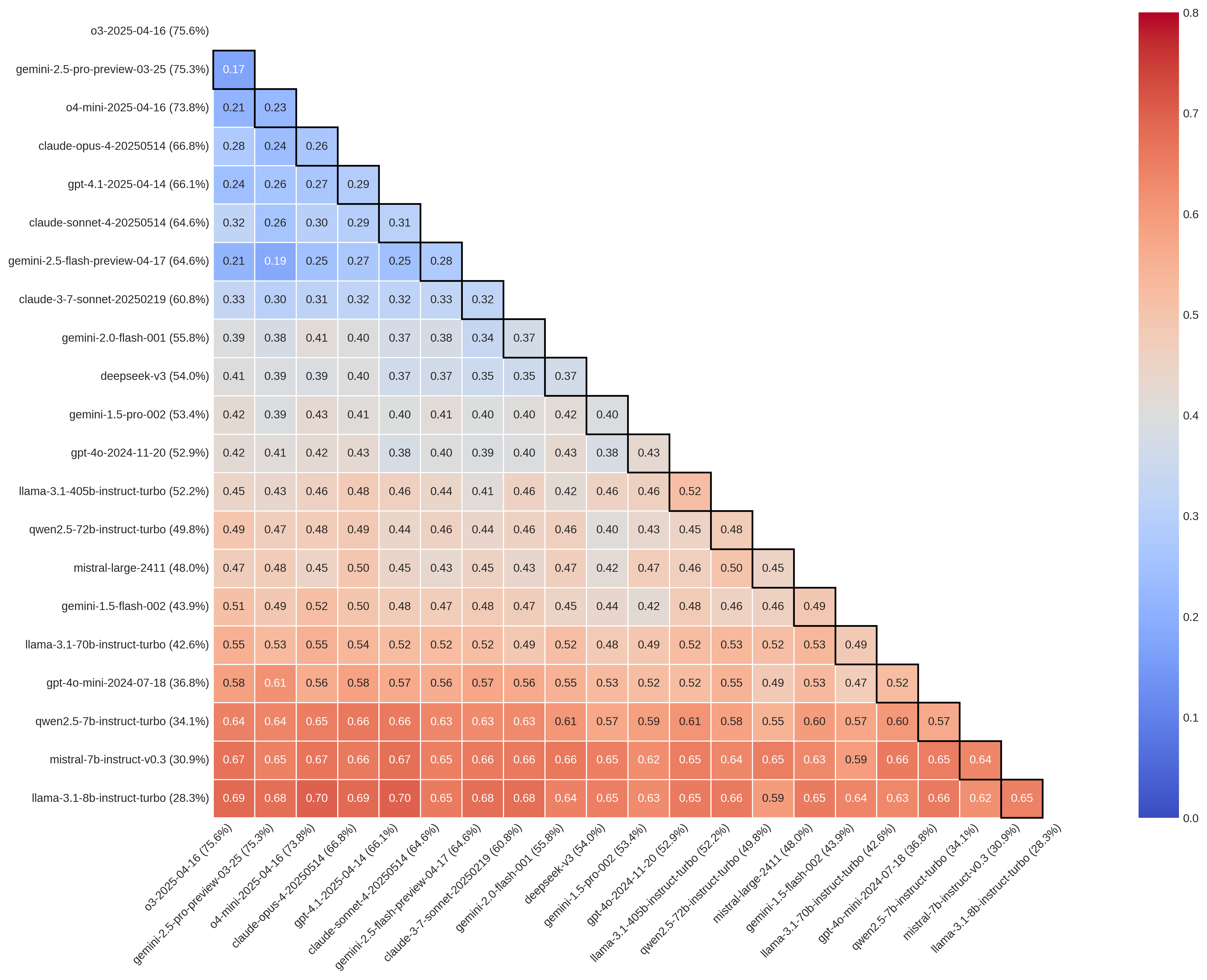
Оценочные наборы данных, такие как MMLU-Pro и GPQA, предназначенные для проверки способностей больших языковых моделей к рассуждениям, подвержены эффекту “иллюзии бенчмарка”. Это явление возникает из-за зависимости этих наборов от аннотированных данных, что может приводить к искусственно завышенной оценке точности моделей. Наблюдаемые уровни разногласий между аннотаторами составляют от 16% до 76% для MMLU-Pro и от 17% до 70% для GPQA, что указывает на субъективность в процессе аннотирования и потенциальную ненадежность результатов оценки, несмотря на высокие заявленные показатели точности моделей.
За Пределами Точности: Оценка Надежности и Согласованности
Высокий уровень разногласий между различными большими языковыми моделями (LLM) при решении одних и тех же задач ставит под сомнение достоверность стандартных оценок точности как показателя стабильной работы. Исследования показывают, что даже при высокой общей точности, модели часто расходятся во мнениях, что свидетельствует о непостоянстве в процессе рассуждений. Этот феномен, известный как “парное несогласие”, указывает на то, что высокая точность не гарантирует воспроизводимость результатов и может быть обманчивым индикатором надежности LLM в критических областях, требующих последовательного и обоснованного анализа данных.
Несоответствие ответов различных больших языковых моделей (LLM) обусловлено не только случайными ошибками, но и, что более важно, систематическими искажениями. Случайные ошибки возникают из-за внутренней неопределенности моделей и приводят к незначительным расхождениям. Однако систематические ошибки, возникающие из-за предвзятости данных, архитектурных особенностей или процесса обучения, значительно усугубляют проблему. Эти систематические отклонения приводят к тому, что разные модели приходят к принципиально разным выводам при анализе одних и тех же данных, что ставит под сомнение надежность полученных результатов и требует критической оценки полученных заключений.
Исследования показали, что непоследовательность в работе больших языковых моделей (LLM) может приводить к существенным расхождениям в научных выводах. В одном из исследований разница в оценке эффекта лечения, полученной с помощью различных LLM, достигла 84%. Более того, зафиксированы случаи, когда модели приходили к противоположным заключениям по сравнению с результатами оригинальных исследований. Это указывает на то, что полагаться исключительно на точность LLM при анализе научных данных может быть ошибочно, поскольку даже незначительные различия в интерпретации могут приводить к значительным отклонениям в выводах и, как следствие, к неверным научным заключениям. Таким образом, необходима осторожность и критическая оценка при использовании LLM в научных исследованиях, особенно когда речь идет о принятии важных решений на основе их результатов.
Оптимизация Вывода для Устойчивости
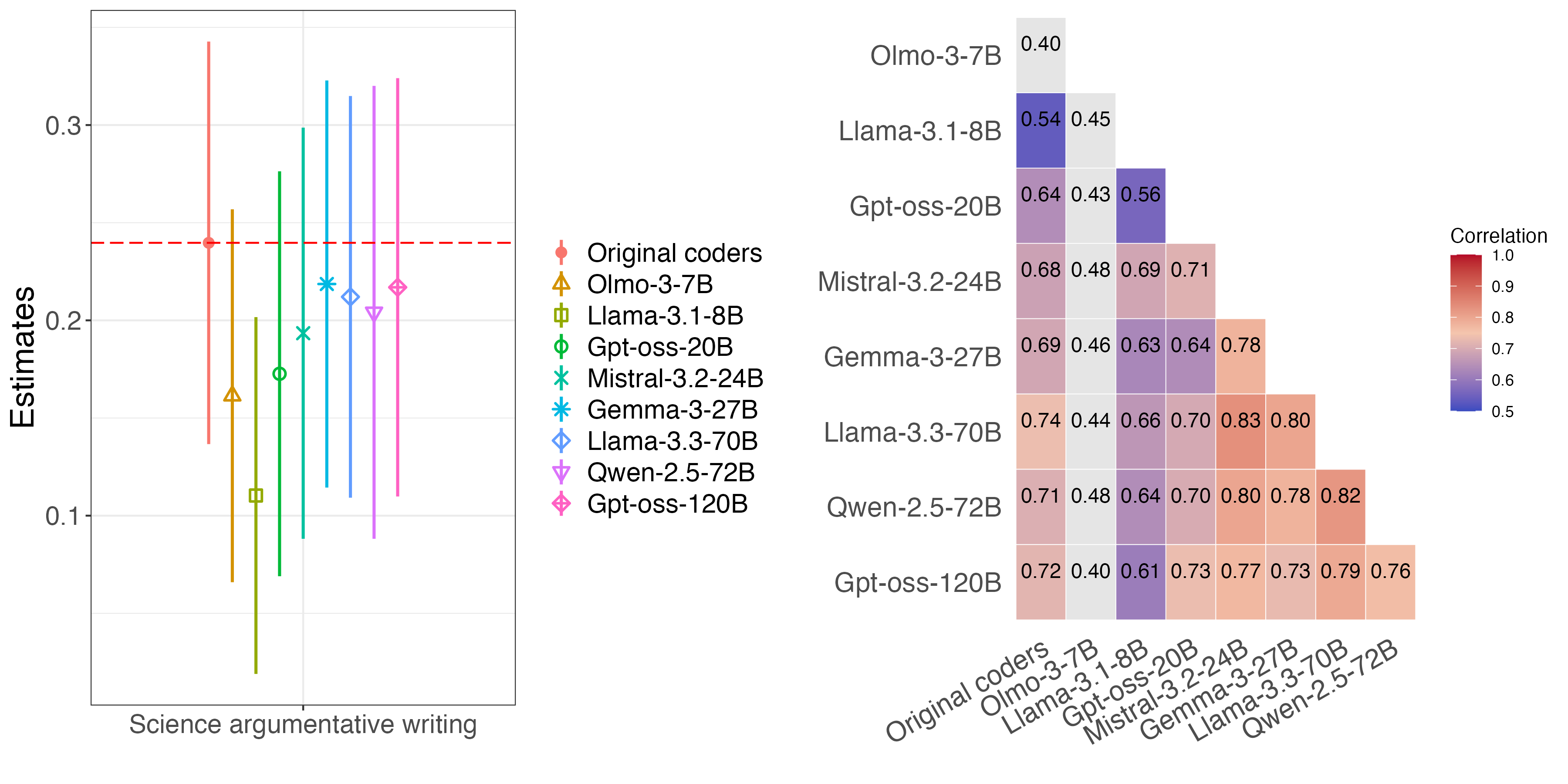
Эффективные движки вывода, такие как ‘VLLM’, играют ключевую роль в функционировании больших языковых моделей (LLM), обеспечивая возможность их практического применения. Однако, несмотря на оптимизацию инфраструктуры и значительные улучшения в скорости обработки, систематические ошибки в ответах LLM сохраняются. Эти ошибки не являются случайными отклонениями, а представляют собой закономерные неточности, проявляющиеся в определенных типах запросов или при обработке специфических данных. Исследования показывают, что даже самые современные LLM подвержены предвзятости, галлюцинациям и неспособности к логическому мышлению в некоторых случаях, что подчеркивает необходимость дальнейшей разработки методов для выявления и смягчения этих систематических проблем, а также создания более надежных и предсказуемых языковых моделей.
Стратегии декодирования, такие как “жадное декодирование” (Greedy Decoding), оказывают существенное влияние на согласованность ответов больших языковых моделей. В то время как “жадное декодирование” отличается высокой скоростью генерации текста, оно может приводить к предсказуемым и повторяющимся ответам, снижая их разнообразие и креативность. Более сложные стратегии, например, выборочное декодирование (sampling) или лучевое декодирование (beam search), позволяют находить более оптимальные решения, но требуют больших вычислительных ресурсов. Тщательный выбор стратегии декодирования, учитывающий баланс между скоростью, качеством и разнообразием генерируемого текста, является критически важным для обеспечения надежности и полезности больших языковых моделей в различных приложениях.
Перспективные исследования в области больших языковых моделей (LLM) должны быть направлены на разработку методов выявления и смягчения систематических ошибок, которые могут возникать даже при оптимизированной инфраструктуре вывода. Недостаточно полагаться на стандартные бенчмарки, поскольку они зачастую не отражают реальную надежность и устойчивость моделей к различным входным данным и контекстам. Необходим переход к более глубокому анализу, позволяющему оценивать не только точность ответов, но и предсказуемость поведения модели, ее склонность к определенным типам ошибок и способность к самокоррекции. Это потребует разработки новых метрик и протоколов тестирования, учитывающих сложность и многогранность LLM, а также создание инструментов для отслеживания и устранения систематических погрешностей в процессе обучения и развертывания моделей.
Исследование показывает, что кажущаяся точность больших языковых моделей может быть обманчива. Модели, демонстрирующие высокие результаты на бенчмарках, зачастую расходятся во мнениях и допускают различные типы ошибок. Это создает иллюзию надежности, в то время как научные выводы, полученные с их помощью, могут быть непоследовательными. Как заметил Кен Томпсон: «В конечном счете, простота — это высшая сложность». Эта фраза отражает суть проблемы: усложнение систем искусственного интеллекта без учета целостной картины приводит к непредсказуемым результатам и ставит под сомнение воспроизводимость исследований. Если система держится на костылях, значит, мы переусложнили её, и это особенно заметно при анализе расхождений между моделями.
Что Дальше?
Представленная работа выявляет иллюзию надежности, свойственную современным бенчмаркам для больших языковых моделей. Высокая производительность, демонстрируемая этими системами, может маскировать существенные разногласия в их рассуждениях и, как следствие, в научных выводах. Эта несовместимость, скрытая за общими показателями точности, указывает на фундаментальную проблему: сложность оценки истинного понимания и способности к обобщению. Подобно тому, как тщательно спроектированная архитектура остается незаметной, пока не подвергается нагрузке, истинная стоимость принятых решений в области разработки моделей проявляется лишь при столкновении с неоднозначностью и новыми данными.
Будущие исследования должны сосредоточиться на разработке методов, позволяющих выявлять и характеризовать эти внутренние разногласия. Необходимо перейти от простой оценки точности к анализу профилей ошибок и исследованию причин их возникновения. Простое увеличение масштаба моделей не решит проблему, если не будет сопровождаться более глубоким пониманием механизмов их работы и принципов, лежащих в основе их рассуждений.
В конечном итоге, надежность научных выводов, полученных с помощью искусственного интеллекта, зависит не от абсолютной точности, а от способности предсказывать и объяснять несогласия. Хорошая архитектура незаметна, пока не ломается, и только тогда видна настоящая цена решений. Игнорирование этой простой истины чревато серьезными последствиями для всей области искусственного интеллекта и науки в целом.
Оригинал статьи: https://arxiv.org/pdf/2602.11898.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Лучшие шаблоны дивизий в Hearts Of Iron 4
- Решение головоломки с паролем Absolum в Yeldrim.
- Шоу 911: Кто такой Рико Прием? Объяснение трибьюта Grip
- Доллар обгонит вьетнамский донг? Эксперты раскрыли неожиданный сценарий
- Прохождение квеста Miles Apart в NTE (Neverness to Everness)
- Все правильные ответы на тест Ghost Station в Neverness to Everness
- Эпизод ‘Dungeons & Dealers’ Теда точно передает опыт D&D.
- Как получить все косметические предметы в REPO
- Лучшее ЛГБТК+ аниме
- Лучшие чертежи Factorio 2.0 | Факторио Космическая эра
2026-02-16 00:24