Автор: Денис Аветисян
Новое исследование выявляет потенциальные бреши в безопасности практических систем квантового распределения ключей, связанные с несовершенством детекторов одиночных фотонов.
Купил акции по совету друга? А друг уже продал. Здесь мы учимся думать своей головой и читать отчётность, а не слушать советы.
Бесплатный телеграм-канал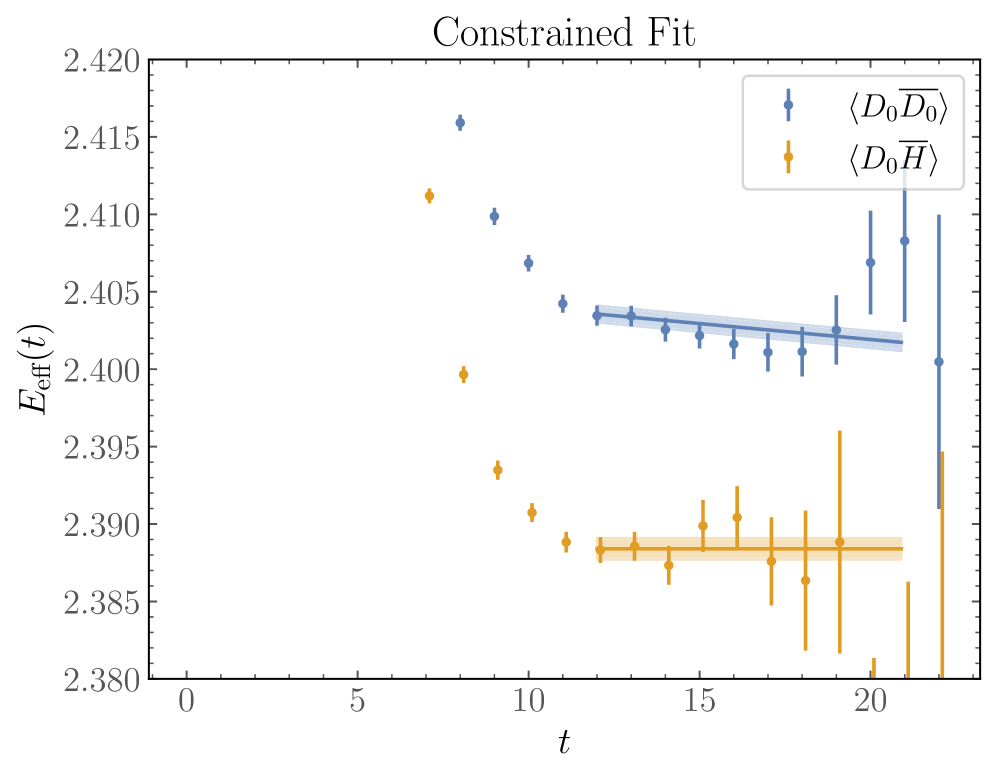
Анализ уязвимостей, обусловленных побочными каналами, в системах квантового распределения ключей и методы их смягчения.
Неопределенности, связанные с возбужденными состояниями, представляют собой серьезную проблему для расчетов в решеточной квантовой хромодинамике (РКХД) многочастичных систем. В работе, озаглавленной ‘Excited-state uncertainties in lattice-QCD calculations of multi-hadron systems’, исследуются новые подходы к оценке систематических ошибок, возникающих при недостаточной доступности временных интервалов для анализа. Предложены более строгие ограничения на энергии, основанные на границах промежуточных состояний, и продемонстрирована их эффективность на примерах расчетов рассеяния нуклонов при m_π \sim 800 МэВ. Способны ли эти методы обеспечить надежные результаты в РКХД спектроскопии и открыть путь к более точному изучению свойств многочастичных адронов?
Эхо Системы: Ограничения Знаний в Больших Моделях
Несмотря на впечатляющие способности к генерации текста и пониманию языка, современные большие языковые модели зачастую испытывают трудности при решении задач, требующих обширных внешних знаний. Это связано с тем, что модели обучаются на огромных объемах текстовых данных, но не обладают механизмом для эффективного извлечения и интеграции информации из внешних источников, таких как базы данных или научные статьи. В результате, при ответе на вопросы, требующие специфических фактов или глубокого понимания предметной области, модели могут выдавать неточные или неполные ответы, демонстрируя ограниченность своих возможностей в контексте реальных задач. Эта проблема особенно актуальна для областей, где знания постоянно обновляются и требуют постоянного доступа к актуальной информации.
Ограничения больших языковых моделей особенно заметны при решении задач, требующих сложного логического вывода и здравого смысла. Исследования показывают, что, несмотря на впечатляющую способность генерировать текст, модели часто допускают ошибки в ситуациях, где необходимы неявные знания о мире и умение делать умозаключения на их основе. Например, при ответе на вопросы, требующие понимания причинно-следственных связей или прогнозирования последствий действий, модели нередко демонстрируют нелогичные или неправдоподобные ответы. Это существенно ограничивает их надежность в критически важных приложениях, таких как медицинская диагностика или финансовый анализ, где даже незначительная ошибка может привести к серьезным последствиям. Таким образом, преодоление сложностей в области сложного и здравого смысла является ключевой задачей для дальнейшего развития и внедрения больших языковых моделей в реальную жизнь.
Преодоление пробелов в знаниях представляется ключевым фактором для реализации всего потенциала больших языковых моделей в практических приложениях. Недостаток доступа к обширной и актуальной информации существенно ограничивает их способность успешно справляться со сложными задачами, требующими не только лингвистических навыков, но и глубокого понимания мира. Устранение этой проблемы позволит создавать системы, способные не просто генерировать текст, но и эффективно решать реальные задачи в различных областях — от медицины и образования до инженерии и научных исследований. Разработка методов, позволяющих LLM эффективно интегрировать внешние базы знаний и постоянно обновлять свои данные, является приоритетной задачей, открывающей путь к созданию действительно интеллектуальных и полезных инструментов.
Усиление Разума: Дополнение LLM Внешними Знаниями
Метод генерации с использованием извлечения (Retrieval Augmented Generation, RAG) представляет собой подход, при котором перед генерацией ответа модель большого языка (LLM) получает релевантную информацию из внешних источников. Этот процесс включает в себя поиск и извлечение данных из баз знаний, документов или других источников, соответствующих запросу пользователя. Извлеченная информация затем включается в контекст запроса, предоставляя LLM дополнительный набор фактов и данных, на основе которых формируется ответ. Использование RAG позволяет расширить возможности LLM за пределы параметров, полученных в процессе обучения, и повысить точность, релевантность и обоснованность генерируемого текста.
Использование внешних источников знаний позволяет значительно расширить базу данных, доступную языковым моделям (LLM). Это, в свою очередь, повышает фактическую точность генерируемых ответов и снижает вероятность возникновения галлюцинаций — выдачи ложной или недостоверной информации. Вместо того чтобы полагаться исключительно на параметры, полученные во время обучения, LLM может обращаться к актуальным данным из внешних баз знаний, документов или веб-ресурсов, что обеспечивает более надежные и обоснованные результаты, особенно в областях, где информация быстро устаревает или требует постоянного обновления.
Методы промпт-инжиниринга, включая побуждение к последовательному мышлению (Chain of Thought Prompting), значительно повышают производительность больших языковых моделей (LLM) за счет структурирования процесса рассуждений. Вместо прямого запроса ответа, промпты, разработанные с использованием Chain of Thought, побуждают модель генерировать промежуточные шаги логических выводов перед выдачей конечного результата. Этот подход позволяет модели не только предоставлять более точные ответы, но и делает процесс принятия решений более прозрачным и объяснимым, а также снижает вероятность ошибок, связанных с неверной интерпретацией входных данных или недостаточным анализом информации. Эффективность данного метода подтверждается экспериментально для широкого спектра задач, включая арифметические вычисления, логические рассуждения и решение проблем, требующих многоступенчатого анализа.
Эффективность Параметров: Адаптация и Тонкая Настройка
Методы адаптации, такие как Adapter Modules и LoRA (Low-Rank Adaptation), представляют собой подходы к эффективной тонкой настройке больших языковых моделей (LLM), направленные на снижение вычислительных затрат при адаптации к конкретным задачам. Вместо обновления всех параметров модели, эти методы вводят небольшое количество дополнительных, обучаемых параметров. Adapter Modules добавляют небольшие слои (адаптеры) в существующую архитектуру LLM, в то время как LoRA замораживает предварительно обученные веса и обучает матрицы низкого ранга, представляющие изменения весов. Это значительно уменьшает количество обучаемых параметров — обычно на несколько порядков — и, следовательно, снижает требования к памяти и вычислительной мощности, необходимые для тонкой настройки, без существенной потери в производительности.
Методы адаптации, такие как адаптерные модули и LoRA, позволяют внедрять новые знания в большую языковую модель (LLM) путем обновления лишь небольшого количества параметров. Вместо переобучения всей модели, эти техники добавляют или модифицируют лишь отдельные слои или веса, что существенно снижает вычислительные затраты и требования к памяти. Это достигается за счет замораживания большей части исходных параметров LLM и обучения лишь небольшого, дополнительного набора параметров, специфичного для целевой задачи. В результате, производительность модели повышается при минимальных инвестициях ресурсов, а возможность повторного использования и комбинирования различных адаптеров способствует более эффективному использованию предварительно обученных LLM.
Эффективность использования параметров является ключевым фактором для развертывания больших языковых моделей (LLM) на устройствах с ограниченными ресурсами, таких как мобильные телефоны или встроенные системы. Традиционное обучение LLM требует значительных вычислительных мощностей и памяти, что делает их непрактичными для многих сценариев. Методы, направленные на повышение эффективности параметров, позволяют снизить объем требуемой памяти и вычислительные затраты, сохраняя при этом приемлемый уровень производительности. Это достигается за счет уменьшения количества обучаемых параметров, что напрямую влияет на возможность масштабирования приложений, использующих LLM, и снижает затраты на инфраструктуру. Повышенная эффективность параметров также способствует более быстрому развертыванию и итерациям моделей, что критически важно для динамично развивающихся областей применения.
Гибкость Разума: Обучение с Малым Количеством Данных
Метод обучения с малым количеством примеров, или Few-Shot Learning, открывает новые возможности для применения больших языковых моделей (LLM) в ситуациях, когда доступ к обширным размеченным наборам данных ограничен или невозможен. Вместо традиционного обучения, требующего тысяч или миллионов примеров для каждой задачи, LLM, использующие этот подход, способны эффективно осваивать новые навыки, основываясь всего на нескольких демонстрационных примерах. Данный метод позволяет модели обобщать знания, полученные при обучении на других, связанных задачах, и применять их к новым ситуациям с высокой точностью. Это значительно снижает затраты на разметку данных и ускоряет процесс адаптации LLM к различным доменам и специфическим требованиям, делая их более доступными и универсальными.
Возможность обучения без единого примера, известная как Zero-Shot Learning, представляет собой революционный прорыв в области больших языковых моделей. Вместо традиционного подхода, требующего обширных наборов размеченных данных для каждой конкретной задачи, эти модели демонстрируют способность обобщать знания и успешно выполнять задания, с которыми они никогда ранее не сталкивались в процессе обучения. Этот феномен достигается за счет глубокого понимания языка и способности к абстракции, позволяющих модели выводить логические связи и применять имеющиеся знания к новым, ранее неизвестным проблемам. По сути, модель не просто запоминает шаблоны, а овладевает принципами, лежащими в основе задач, что открывает невероятные перспективы для адаптации к широкому спектру областей и решения задач, которые ранее считались недоступными для автоматизации.
Способность моделей к обучению с малым количеством примеров и без примеров играет ключевую роль в расширении сферы их применения. Это позволяет адаптировать большие языковые модели к новым областям знаний и решать задачи, для которых ранее не существовало размеченных данных. Например, модель, обученная на анализе медицинских текстов на английском языке, может быть адаптирована для обработки русскоязычной медицинской документации, используя лишь небольшое количество примеров переводов или специализированных терминов. Такая гибкость критически важна для быстрого внедрения LLM в новые индустрии и для решения задач, которые постоянно возникают в динамично меняющемся мире, где сбор больших объемов данных часто невозможен или нецелесообразен.
Изучение уязвимостей практических систем квантового распределения ключей, как представлено в данной работе, напоминает о неизбежном взрослении любой сложной системы. Подобно тому, как несовершенства в однофотонных детекторах создают лазейки для атак, любая архитектурная модель несет в себе пророчество о будущих сбоях. Джон Дьюи некогда заметил: «Образование — это не подготовка к жизни; образование — это сама жизнь». Так и здесь, поиск методов смягчения атак — это не просто защита информации, а непрерывный процесс адаптации и совершенствования самой системы безопасности, ее естественный путь развития. Исследование, посвященное уязвимостям, подобно рефакторингу — начинается как молитва о стабильности и завершается покаянием перед лицом неизбежных компромиссов.
Что Дальше?
Представленная работа, подобно тщательному зондированию трещин в монолите, выявляет не столько уязвимости, сколько неизбежные точки напряжения в любой практической реализации квантового распределения ключей. Упор на несовершенства однофотонных детекторов — это не поиск «решения», а признание того, что система всегда будет отражать хаотичное взаимодействие её компонентов. Более совершенные детекторы — лишь отсрочка, а не отмена, приближающегося момента, когда шум системы станет доминировать над сигналом.
Попытки «усилить» защиту за счет усложнения протоколов и алгоритмов кажутся тщетными. Система не ломается — она эволюционирует в неожиданные формы, обнаруживая новые векторы атак, которые невозможно предвидеть на этапе проектирования. Реальная задача — не построить неприступную крепость, а создать экосистему, способную к быстрой адаптации и самовосстановлению, пусть и ценой периодических, контролируемых сбоев.
Будущие исследования, вероятно, сконцентрируются на разработке систем, которые не стремятся к абсолютной безопасности, а принимают неизбежность ошибок и учатся извлекать из них пользу. Возможно, истинный прогресс заключается не в улучшении детекторов, а в создании методов анализа и интерпретации шума, превращая его из угрозы в источник информации. Долговременная стабильность — признак скрытой катастрофы; истинная устойчивость — в постоянном движении.
Оригинал статьи: https://arxiv.org/pdf/2601.22272.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Лучшие шаблоны дивизий в Hearts Of Iron 4
- Решение головоломки с паролем Absolum в Yeldrim.
- Лучшее оружие, броня и аксессуары, которые стоит получить в начале Crimson Desert.
- Раскрытие удивительных истин о «Доме Давида» на Амазонке!
- Шоу 911: Кто такой Рико Прием? Объяснение трибьюта Grip
- Лучшее ЛГБТК+ аниме
- Наследие Кузницы в KCD2: 13 Новых Оружий, Ранжированных и Расположения
- В ролях: приглашенные звезды и актеры 22-го сезона 3-й серии «Морской полиции» (фотографии) – Донна Миллс в беде с Хэлом
- Skyrim: 23 лучшие жены и как на них жениться
- Как пройти I’m Not a Robot – полное прохождение всех уровней
2026-02-02 23:39